Frontiers in Computational Neuroscience
Wprowadzenie
Ostatnio zaproponowaliśmy mechanizm asocjacyjnego odzyskiwania informacji, który jawnie uwzględnia długoterminowe neuronalne reprezentacje elementów pamięci (Romani i in., 2013). Jednym z podstawowych przewidywań tego modelu jest istnienie „łatwych” i „trudnych” słów. Przewidywanie to zostało zweryfikowane w naszej analizie dużego zbioru danych z eksperymentów swobodnego przypominania zebranych w laboratorium Michaela Kahany, gdzie pokazaliśmy, że prawdopodobieństwa przypominania słów są spójne pomiędzy dowolnie wybranymi grupami badanych (Katkov i in., submitted). Naturalnym pytaniem postawionym przez te obserwacje jest to, jakie cechy są predykcyjne dla trudności słów w eksperymentach z zapamiętywaniem, w szczególności jaki, jeśli w ogóle, jest wkład długości słowa.
Większość poprzednich badań nad efektem długości słowa używała list, które składały się z krótkich lub długich słów. W dwóch poprzednich badaniach, w których używano list składających się na przemian z krótkich i długich słów, nie zaobserwowano efektu długości słowa (Hulme i in., 2004; Jalbert i in., 2011). Nasz obecny wkład wykorzystuje paradygmat swobodnego przypominania i jest oparty na znacznie większym zbiorze danych niż poprzednie badania. Stwierdzamy, że gdy słowa są wybierane losowo, niezależnie od ich długości, długie słowa są zapamiętywane lepiej niż krótkie, co stanowi pozorne zaprzeczenie klasycznego efektu długości słów zarówno w seryjnym, jak i swobodnym zapamiętywaniu (Baddeley i in., 1975; Russo i Grammatopoulou, 2003; Tehan i Tolan, 2007; Bhatarah i in., 2009). Przedstawiamy możliwe rozwiązanie tej sprzeczności w ramach asocjacyjnego modelu przywoływania (Romani i in., 2013).
Materiały i metody
Metody eksperymentalne
Dane przedstawione w tym manuskrypcie zostały zebrane w laboratorium M. Kahany w ramach Penn Electrophysiology of Encoding and Retrieval Study (szczegóły eksperymentów zob. Miller i in., 2012). Analizujemy tu wyniki 141 uczestników (w wieku 17-30 lat), którzy ukończyli pierwszą fazę eksperymentu, składającą się z siedmiu sesji eksperymentalnych. Uczestnicy uzyskali zgodę zgodnie z protokołem IRB Uniwersytetu Pensylwanii i otrzymali wynagrodzenie za udział. Każda sesja składała się z 16 list 16 słów prezentowanych pojedynczo na ekranie komputera i trwała około 1,5 h. Po każdej badanej liście następował natychmiastowy test pamięci dowolnej. Słowa były losowane z puli 1638 słów. W przypadku każdej listy występowało 1500 ms opóźnienia przed pojawieniem się na ekranie pierwszego słowa. Każda pozycja była wyświetlana na ekranie przez 3000 ms, po czym następowała przerwa między bodźcami 800-1200 ms (rozkład równomierny). Po ostatniej pozycji na liście następowało 1200-1400 ms opóźnienia jitterowego, po którym uczestnik otrzymywał 75 s na próbę przypomnienia sobie którejkolwiek z właśnie prezentowanych pozycji. Wszystkie próby zostały wykorzystane; intruzje i powtórzenia zostały usunięte z prób.
Model
Zakładamy, że każde słowo jest reprezentowane przez losowo wybraną populację neuronów w dedykowanej sieci pamięci. Zakładamy również, że każdy z odzyskanych elementów działa jako wewnętrzna wskazówka dla następnego, zgodnie z miarą podobieństwa pomiędzy elementami, która jest zdefiniowana jako wielkość przecięcia pomiędzy odpowiednimi populacjami (liczba neuronów, które reprezentują oba elementy). Idąc za (Romani i in., 2013), rozważamy proces retrieval, który jest bezpośrednio zdeterminowany przez reprezentacje pamięciowe pozycji, bez jawnej symulacji aktywności sieci. Dynamika pobierania opisana jest przez sekwencję przywoływanych pozycji. Pierwszy z nich wybierany jest losowo spośród prezentowanych, a każdy kolejny przywoływany element wybierany jest jako ten, który ma maksymalne podobieństwo do aktualnie przywoływanego, nie licząc tylko elementu „odwiedzanego” (Romani i in., 2013). Przywoływanie zostaje zakończone, gdy proces przywoływania wejdzie w cykl i nie będzie można przywołać więcej elementów.
Aby naśladować protokół eksperymentalny (patrz wyżej), wygenerowaliśmy W = 1638 losowych wzorców binarnych o długości N: {ξiw = 0; 1} z w = 1, … , W; i = 1, … , N oznacza neurony w sieci, takie, że ξiw = 1, jeśli neuron i uczestniczy w kodowaniu elementu pamięci w. Podobieństwo między pozycjami w i w′ jest następnie obliczane jako Sww′=∑i=1Nξiwξiw′. Komponenty wzorca dla każdej pozycji były losowane niezależnie z prawdopodobieństwem pw wynoszącym ξiw = 1 wybranym w następujący sposób: każdemu wzorcowi arbitralnie przypisano długość sylabiczną lw = 1…4, tak by rozkład lw we wzorcach odpowiadał odpowiedniemu rozkładowi w słowach użytych w eksperymencie (pięć słów o długości sylabicznej większej niż cztery połączono z tymi o długości cztery). Dla wzorców o danym lw, odpowiadające im pw były równomiernie rozłożone od 0,02 – 10-3lw do 0,02 + 10-3lw. Przy takim wyborze statystyki wzorca, średnia liczba neuronów reprezentujących daną pozycję nie zależy od jej długości sylabicznej, natomiast wariancja rośnie wraz z długością sylabiczną. Reprezentacje słów były więc stałe przez cały czas trwania symulowanego eksperymentu.
Dla każdej symulowanej próby przypominania, L = 16 pozycji było wybieranych do prezentacji zgodnie z dwoma protokołami eksperymentalnymi. W pierwszym z nich, elementy były wybierane całkowicie niezależnie, tak jak w eksperymencie Kahany. W drugim protokole elementy o tym samym lw były wybierane losowo. Proces przypominania był symulowany jak w (Romani i in., 2013). Pierwsza przywoływana pozycja była losowo wybierana spośród prezentowanych. Kolejne przejścia między przywoływanymi pozycjami były określane przez macierz podobieństwa S między nimi, której każdy element był obliczany jako liczba neuronów w przecięciu między odpowiednimi reprezentacjami: Sww′=∑i=1Nξiwξiw′. Dokładniej, następny pobierany element to ten, który ma maksymalne podobieństwo do aktualnie pobieranego, z wyłączeniem elementu, który był pobierany tuż przed bieżącym. Przywoływanie kończy się, gdy proces pobierania wejdzie w cykl i nie będzie można pobrać więcej elementów.
Wyniki
Przeanalizowaliśmy duży zbiór danych eksperymentów swobodnego przywoływania, wykonanych przez 141 osób, po 112 prób na osobę. Dane te zostały zebrane w laboratorium Michaela Kahany. Listy składały się z 16 słów wybranych losowo z puli 1638 słów. Wykorzystano wszystkie próby; z prób usunięto intruzje i powtórzenia (w sumie 15792 próby, zob. rozdział Metody). Dla każdego słowa obliczano jego ogólne prawdopodobieństwo przypomnienia (Prec) jako frakcję prób, w których słowo to zostało przypomniane, gdy było prezentowane. Rysunek 1 przedstawia rozkład (Prec) dla wszystkich słów mających daną liczbę sylab (kolor czarny), zagregowanych ze wszystkich prób. Rozkład Prec jest szeroki dla wszystkich długości słów. Niemniej jednak, średnie prawdopodobieństwo przypomnienia oraz jego wariancja rosną monotonicznie wraz ze wzrostem liczby sylab (współczynnik korelacji 0,15, p < 10-6).
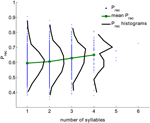
Rysunek 1. Prawdopodobieństwo przypomnienia dla słów o różnej liczbie sylab (niebieskie kropki), rozkład prawdopodobieństwa przypomnienia (czarny) oraz średnia wartość prawdopodobieństwa przypomnienia (zielony) obliczona na podstawie danych eksperymentalnych. Współczynnik korelacji między liczbą sylab a prawdopodobieństwem przypomnienia wynosi 0,15, p < 10-6).
Ten wynik pozornie zaprzecza klasycznemu efektowi długości słowa, gdzie listy krótkich słów były zapamiętywane lepiej niż listy dłuższych słów (Baddeley i in., 1975; Russo i Grammatopoulou, 2003; Tehan i Tolan, 2007; Bhatarah i in., 2009). Aby sprawdzić, czy oba te efekty mogą być wyjaśnione przez zaproponowany przez nas mechanizm pobierania danych, przeprowadziliśmy symulację modelu imitującego paradygmaty eksperymentalne w dwóch warunkach – bez zapamiętywania z listami złożonymi z krótkich/długich słów oraz z listami losowymi (zob. Metody). Uzyskaliśmy zaskakujący wynik: wyniki w zadaniu free-recall zależą od paradygmatu eksperymentalnego – w przywołaniu losowej mieszaniny niepowiązanych ze sobą słów dłuższe słowa są statystycznie łatwiejsze do przywołania, podczas gdy w przypadku list złożonych ze słów o stałej liczbie sylab krótsze słowa są łatwiejsze do przywołania (Rysunek 2).
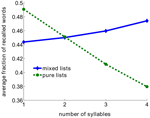
Rysunek 2. Średnia frakcja przywoływanych słów jako funkcja liczby sylab w modelu. Listy czyste są tworzone z użyciem tylko słów o tej samej liczbie sylab. Listy mieszane są tworzone z całej puli słów.
Większość wyjaśnień klasycznych efektów długości słów zakłada, że całkowita długość prezentowanych bodźców jest ujemnie skorelowana z liczbą przywoływanych słów. Aby sprawdzić, czy stwierdzenie to znajduje potwierdzenie w danych, obliczyliśmy korelację między liczbą sylab w prezentowanych listach a liczbą przypominanych słów. Stwierdziliśmy praktycznie brak korelacji (współczynnik korelacji wynosi 0,004 i nie jest istotnie różny od 0, p = 0,67).
Dyskusja
Efekt długości słów, czyli obserwacja, że listy krótkich słów są zapamiętywane lepiej niż listy długich słów (Baddeley i in., 1975), jest uważany za jedno z kluczowych zjawisk w teoriach pamięci krótkotrwałej (Campoy, 2011; Jalbert i in., 2011). Tutaj donosimy, że w swobodnym przypominaniu sobie niepowiązanych słów, gdzie krótkie i długie słowa są losowo mieszane, długie słowa mają wyższe prawdopodobieństwo przypomnienia niż krótkie, co wydaje się zaprzeczać efektowi długości słowa.
Klasyczny efekt długości słowa jest tradycyjnie wyjaśniany albo przez zwiększoną złożoność dłuższych pozycji (Neath i Nairne, 1995), albo przez zwiększony czas próby dłuższych pozycji (Baddeley, 1986, 2003; Page i Norris, 1998; Burgess i Hitch, 1999). Pierwszy sposób sugeruje, że krótsze słowa są generalnie łatwiejsze do przypomnienia, co nie jest zgodne z naszymi obserwacjami. W drugim przypadku, ze względu na krótszy czas próby, więcej krótkich słów może być powtórzonych, a zatem więcej z nich jest przywoływanych. Wyjaśnienie to nie precyzuje, w jakiej kolejności należałoby próbować prezentowane słowa, ale sugeruje ujemną korelację między całkowitą długością prezentowanych pozycji a liczbą przywoływanych słów, podczas gdy w danych taka korelacja nie występuje.
Pokazujemy tutaj, że nasz niedawno zasugerowany mechanizm asocjacyjnego pobierania informacji może potencjalnie tłumaczyć zarówno klasyczny efekt długości słowa (który jest również obecny w eksperymentach swobodnego przywoływania, zob. Russo i Grammatopoulou, 2003; Bhatarah i in., 2009), jak i przeciwstawny efekt długości na listach losowo wybranych słów, opisany w tym artykule. W przeciwieństwie do istniejących modeli, długoterminowa neuronalna reprezentacja pozycji odgrywa kluczową rolę w naszym modelu i nie jest wymagany żaden oddzielny mechanizm pamięci krótkotrwałej. W szczególności, prawdopodobieństwo przywołania pozycji na losowych listach rośnie wraz z wielkością jej reprezentacji w stosunku do innych pozycji, a pozycje te są przywoływane wcześniej i wypierają pozycje o mniejszych reprezentacjach (Romani i in., 2013). Średnie prawdopodobieństwo przywołania całej puli pozycji jest jednak niezależne od średniej wielkości reprezentacji, ale wiąże się ujemnie z wariancją wielkości reprezentacji w całej puli (Katkov i in., submitted). Założyliśmy zatem, że dłuższe słowa nie mają przeciętnie większej reprezentacji niż krótsze, ale mają kolektywnie większą wariancję wielkości reprezentacji. Założenie to nie ma obecnie bezpośredniego uzasadnienia biologicznego, ale pozwoliło nam pogodzić pozorną sprzeczność między obserwacjami eksperymentalnymi. W szczególności, wyjaśnia ono klasyczny efekt długości słowa, gdzie prezentowane są tylko słowa o danej długości sylabicznej, a zatem wariancja wielkości reprezentacji wzrasta wraz z długością sylabiczną. Na listach o mieszanej długości sylabicznej, w niektórych próbach pozycje o dłuższej długości sylabicznej mają największą reprezentację neuronalną. Kiedy takie listy są prezentowane, dłuższe słowa mają większe prawdopodobieństwo przywołania, tłumiąc inne pozycje, co skutkuje łagodną dodatnią korelacją między długością sylabiczną pozycji a prawdopodobieństwem jej przywołania.
Wyniki przedstawione w tym artykule pokazują, że długość słowa jest istotnym czynnikiem wpływającym na łatwość jego przywołania. Zauważamy jednak, że prawdopodobieństwo przywołania wciąż wykazuje szeroki rozkład nawet dla słów o danej długości, co wskazuje, że inne, jeszcze nieznane cechy słowa również przyczyniają się do prawdopodobieństwa jego przywołania.
Oświadczenie o konflikcie interesów
Autorzy deklarują, że badania zostały przeprowadzone przy braku jakichkolwiek komercyjnych lub finansowych powiązań, które mogłyby być interpretowane jako potencjalny konflikt interesów.
Podziękowania
Jesteśmy wdzięczni M. Kahanie za szczodre podzielenie się z nami danymi uzyskanymi w jego laboratorium. Laboratorium Kahany jest wspierane przez NIH grant MH55687. Misha Tsodyks jest wspierany przez EU FP7 (Grant agreement 604102), Israeli Science Foundation i Foundation Adelis. Sandro Romani jest wspierany przez Human Frontier Science Program long-term fellowship.
Baddeley, A. D. (1986). Working Memory. Oxford, Anglia: Oxford University Press.
Baddeley, A. D. (2003). Pamięć robocza i język: przegląd. J. Commun. Disord. 36, 189-208. doi: 10.1016/s0021-9924(03)00019-4
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Baddeley, A. D., Thomson, N., and Buchanan, M. (1975). Word length and the structure of short-term memory. J. Verbal Learn. Verbal Behav. 14, 575-589. doi: 10.1016/s0022-5371(75)80045-4
CrossRef Full Text | Google Scholar
Bhatarah, P., Ward, G., Smith, J., and Hayes, L. (2009). Examining the relationship between free recall and immediate serial recall: similar patterns of rehearsal and similar effects of word length, presentation rate and articulatory suppression. Mem. Cognit. 37, 689-713. doi: 10.3758/MC.37.5.689
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Burgess, N., and Hitch, G. (1999). Memory for serial order: a network model of the phonological loop and its timing. Psychol. Rev. 106, 551-581. doi: 10.1037//0033-295x.106.3.551
CrossRef Full Text | Google Scholar
Campoy, G. (2011). Interferencja retroaktywna w pamięci krótkotrwałej i efekt długości słowa. Acta Psychol. (Amst) 138, 135-142. doi: 10.1016/j.actpsy.2011.05.016
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Hulme, C., Suprenant, A. M., Bireta, T. J., Stuart, G., and Neath, I. (2004). Abolishing the word-length effect. J. Exp. Psychol. Learn. Mem. Cogn. 30, 98-106. doi: 10.1037/0278-7393.30.1.98
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Jalbert, A., Neath, I., Bireta, T. J., and Surprenant, A. M. (2011). When does length causes the word length effect? J. Exp. Psychol. Learn. Mem. Cogn. 37, 338-353. doi: 10.1037/a0021804
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Miller, J. F., Kahana, M. J., and Weidemann, C. T. (2012). Zakończenie przypominania w swobodnym zapamiętywaniu. Mem. Cogn. 40, 540-550. doi: 10.3758/s13421-011-0178-9
CrossRef Full Text | Google Scholar
Neath, I., and Nairne, J. S. (1995). Efekty długości słów w pamięci natychmiastowej: nadpisywanie teorii zanikania śladów. Psychon. Bull. Rev. 2, 429-441. doi: 10.3758/bf03210981
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Page, M. P. A., and Norris, D. (1998). The primacy model: a new model of immediate serial recall. Psychol. Rev. 105, 761-781. doi: 10.1037//0033-295x.105.4.761-781
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Romani, S., Pinkoviezky, I., Rubin, A., and Tsodyks, M. (2013). Scaling laws of associative memory retrieval. Neural Comput. 25, 2523-2544. doi: 10.1162/NECO_a_00499
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Russo, R., and Grammatopoulou, N. (2003). Word length and articulatory suppression affect short-term and long-term recall tasks. Mem. Cognit. 31, 728-737. doi: 10.3758/bf03196111
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Tehan, G., and Tolan, G. A. (2007). Efekty długości słów w pamięci długotrwałej. J. Mem. Lang. 56, 35-48. doi: 10.1016/j.jml.2006.08.015
CrossRef Full Text | Google Scholar
.