Frontiers in Computational Neuroscience
Introduzione
Di recente abbiamo proposto un meccanismo di recupero associativo delle informazioni che tiene esplicitamente conto delle rappresentazioni neuronali a lungo termine degli elementi di memoria (Romani et al., 2013). Una delle previsioni di base del modello è l’esistenza di parole “facili” e “difficili”. Questa previsione è stata verificata nella nostra analisi di un ampio dataset di esperimenti di richiamo libero raccolti nel laboratorio di Michael Kahana, dove abbiamo dimostrato che le probabilità di parole da richiamare sono coerenti tra gruppi arbitrariamente scelti di soggetti (Katkov et al., presentato). La domanda naturale posta da queste osservazioni è quali caratteristiche sono predittive della difficoltà delle parole negli esperimenti di richiamo, in particolare qual è l’eventuale contributo della lunghezza delle parole.
La maggior parte degli studi precedenti sull’effetto della lunghezza delle parole ha utilizzato liste composte specificamente da parole corte o lunghe. In due studi precedenti in cui sono state utilizzate liste composte alternativamente da parole corte e lunghe, non è stato osservato alcun effetto della lunghezza delle parole (Hulme et al., 2004; Jalbert et al., 2011). Il nostro attuale contributo utilizza il paradigma del richiamo libero e si basa su un set di dati molto più ampio rispetto agli studi precedenti. Riportiamo che quando le parole sono selezionate in modo casuale, indipendentemente dalla loro lunghezza, le parole lunghe sono richiamate meglio di quelle corte, in un’apparente contraddizione con il classico effetto di lunghezza delle parole sia nel richiamo seriale che libero (Baddeley et al., 1975; Russo e Grammatopoulou, 2003; Tehan e Tolan, 2007; Bhatarah et al., 2009). Forniamo una possibile risoluzione di questa contraddizione nel quadro del modello di recupero associativo di (Romani et al., 2013).
Materiali e metodi
Metodi sperimentali
I dati riportati in questo manoscritto sono stati raccolti nel laboratorio di M. Kahana come parte del Penn Electrophysiology of Encoding and Retrieval Study (vedi Miller et al., 2012 per i dettagli degli esperimenti). Qui abbiamo analizzato i risultati dei 141 partecipanti (età 17-30) che hanno completato la prima fase dell’esperimento, composta da sette sessioni sperimentali. I partecipanti hanno dato il loro consenso secondo il protocollo IRB dell’Università della Pennsylvania e sono stati compensati per la loro partecipazione. Ogni sessione consisteva in 16 liste di 16 parole presentate una alla volta sullo schermo di un computer e durava circa 1,5 ore. Ogni lista di studio era seguita da un test di richiamo libero immediato. Le parole sono state prese da un pool di 1638 parole. Per ogni lista, c’era un ritardo di 1500 ms prima che la prima parola apparisse sullo schermo. Ogni elemento era sullo schermo per 3000 ms, seguito da un intervallo interstimolo di 800-1200 ms (distribuzione uniforme). Dopo l’ultimo elemento della lista, c’era un ritardo di 1200-1400 ms con jitter, dopo il quale al partecipante venivano dati 75 s per tentare di ricordare uno qualsiasi degli elementi appena presentati. Tutte le prove sono state utilizzate; le intrusioni e le ripetizioni sono state rimosse dalle prove.
Il modello
Assumiamo che ogni parola sia rappresentata da una popolazione di neuroni scelta a caso nella rete di memoria dedicata. Assumiamo inoltre che ogni elemento recuperato agisca come spunto interno per quello successivo in base alla misura della somiglianza tra gli elementi, che è definita come la dimensione dell’intersezione tra le popolazioni corrispondenti (il numero di neuroni che rappresentano entrambi gli elementi). Seguendo (Romani et al., 2013), consideriamo il processo di recupero che è direttamente determinato dalle rappresentazioni di memoria degli elementi, senza simulare esplicitamente l’attività di rete. La dinamica del recupero è descritta da una sequenza di elementi richiamati. Il primo è scelto casualmente tra quelli presentati, e ogni successivo elemento richiamato è scelto per essere quello che ha una massima somiglianza con quello attualmente richiamato, senza contare gli elementi appena “visitati” (Romani et al., 2013). Il richiamo viene terminato quando il processo di recupero entra in un ciclo e non è più possibile recuperare altri elementi.
Per imitare il protocollo sperimentale (vedi sopra), abbiamo generato W = 1638 modelli binari casuali di lunghezza N: {ξiw = 0; 1} con w = 1, … , W; i = 1, … , N indica i neuroni della rete, in modo tale che ξiw = 1 se il neurone i partecipa alla codifica dell’elemento di memoria w. La similarità tra gli elementi w e w′ è quindi calcolata come Sww′=∑i=1Nξiwξiw′. Le componenti del pattern per ogni elemento sono state estratte indipendentemente con la probabilità pw di ξiw = 1 scelta nel modo seguente: ad ogni pattern è stata arbitrariamente assegnata una lunghezza sillabica lw = 1…4 tale che la distribuzione di lw nei pattern corrispondesse alla corrispondente distribuzione nelle parole usate nell’esperimento (cinque parole con lunghezza sillabica maggiore di quattro sono state combinate con quelle di lunghezza quattro). Per i pattern con lw data, i pw corrispondenti erano distribuiti in modo equidistante da 0,02 – 10-3lw a 0,02 + 10-3lw. Con questa scelta di statistiche di pattern, il numero medio di neuroni che rappresentano un dato elemento non dipende dalla sua lunghezza sillabica, mentre la varianza aumenta con la lunghezza sillabica. Le rappresentazioni delle parole erano quindi fisse per tutta la durata dell’esperimento simulato.
Per ogni prova di richiamo simulata, L = 16 elementi sono stati scelti per la presentazione secondo due protocolli sperimentali. Per il primo, gli elementi sono stati selezionati in modo completamente indipendente, come nell’esperimento di Kahana. Per il secondo protocollo, gli elementi con lo stesso lw sono stati selezionati in modo casuale. Il processo di richiamo è stato simulato come in (Romani et al., 2013). Il primo elemento richiamato è stato scelto a caso tra quelli presentati. Le successive transizioni tra gli elementi richiamati erano determinate dalla matrice di similarità S tra di loro, ogni elemento della quale era calcolato come il numero di neuroni nell’intersezione tra le rappresentazioni corrispondenti: Sww′=∑i=1Nξiwξiw′. Più specificamente, il prossimo elemento recuperato è quello che ha la massima somiglianza con quello attualmente recuperato, escludendo l’elemento che è stato recuperato appena prima di quello attuale. Il richiamo viene terminato quando il processo di recupero entra in un ciclo e non è più possibile recuperare altri elementi.
Risultati
Abbiamo analizzato un ampio dataset di esperimenti di richiamo libero eseguiti da 141 soggetti con 112 prove per soggetto. I dati sono stati raccolti nel laboratorio di Michael Kahana. Le liste erano composte da 16 parole scelte a caso da un pool di 1638 parole. Tutte le prove sono state utilizzate; intrusioni e ripetizioni sono state rimosse dalle prove (in totale 15792 prove, vedi sezione Metodi). Per ogni parola, la sua probabilità complessiva di richiamo (Prec) è stata calcolata come la frazione di prove in cui questa parola è stata richiamata quando è stata presentata. La figura 1 mostra la distribuzione di (Prec) per tutte le parole con un dato numero di sillabe (in nero) aggregate da tutte le prove. La distribuzione di Prec è ampia per tutte le lunghezze di parole. Tuttavia, la probabilità media di richiamo e la sua varianza crescono monotonamente con il numero di sillabe (il coefficiente di correlazione è 0,15, p < 10-6).
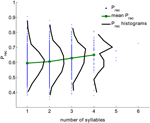
Figura 1. Probabilità di richiamo per parole con diverso numero di sillabe (punti blu), la distribuzione delle probabilità di richiamo (nero) e il valore medio della probabilità di richiamo (verde) calcolato dai dati sperimentali. Il coefficiente di correlazione tra il numero di sillabe e la probabilità di richiamo è 0,15, p < 10-6).
Questo risultato contraddice apparentemente l’effetto classico della lunghezza delle parole, in cui le liste di parole brevi hanno dimostrato di essere richiamate meglio delle liste di parole più lunghe (Baddeley et al., 1975; Russo e Grammatopoulou, 2003; Tehan e Tolan, 2007; Bhatarah et al., 2009). Per verificare se entrambi questi effetti possono essere spiegati dal meccanismo di recupero da noi proposto, abbiamo simulato il modello imitando paradigmi sperimentali in due condizioni di richiamo libero con liste composte da parole corte/lunghe e liste casuali (vedi Metodi). Il risultato sorprendente è emerso: la performance nel compito di free-recall dipende dal paradigma sperimentale – nel richiamo di miscele casuali di parole non correlate, le parole più lunghe sono statisticamente più facili da richiamare, mentre nelle liste composte da parole con un numero fisso di sillabe, le parole più corte sono più facili da richiamare (Figura 2).
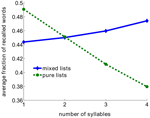
Figura 2. Frazione media di parole richiamate in funzione del numero di sillabe nel modello. Le liste pure sono composte usando solo parole con lo stesso numero di sillabe. Le liste miste sono composte dall’intero pool di parole.
La maggior parte delle spiegazioni degli effetti classici della lunghezza delle parole assume che la lunghezza totale degli stimoli presentati sia negativamente correlata al numero di parole richiamate. Per verificare se questa affermazione è supportata dai dati, abbiamo calcolato la correlazione tra il numero di sillabe nelle liste presentate e il numero di parole richiamate. Non abbiamo trovato praticamente nessuna correlazione (il coefficiente di correlazione è 0,004 e non è significativamente diverso da 0, p = 0,67).
Discussione
L’effetto della lunghezza delle parole, cioè l’osservazione che liste di parole corte sono richiamate meglio di liste di parole lunghe (Baddeley et al., 1975) è considerato uno dei fenomeni chiave nelle teorie della memoria a breve termine (Campoy, 2011; Jalbert et al., 2011). Qui riportiamo che nel richiamo libero di parole non correlate, dove parole corte e lunghe sono mescolate casualmente, le parole lunghe hanno una probabilità di richiamo più alta di quelle corte, in apparente contraddizione con l’effetto lunghezza parola.
Il classico effetto lunghezza parola è tradizionalmente spiegato da una maggiore complessità degli elementi più lunghi (Neath e Nairne, 1995), o un maggiore tempo di prova degli elementi più lunghi (Baddeley, 1986, 2003; Page e Norris, 1998; Burgess e Hitch, 1999). Il primo account suggerisce che le parole più corte sono genericamente più facili da ricordare, il che non è compatibile con la nostra osservazione. Nel secondo conto, più parole brevi possono essere provate, a causa del tempo di prova più breve, e quindi più di esse sono richiamate. Questa spiegazione non specifica in quale ordine si provino le parole presentate, ma suggerisce una correlazione negativa tra la lunghezza totale degli elementi presentati e il numero di parole richiamate, mentre tale correlazione non esiste nei dati.
Qui mostriamo che il nostro meccanismo di recupero associativo recentemente suggerito può potenzialmente spiegare sia il classico effetto di lunghezza delle parole (che è presente anche negli esperimenti di richiamo libero, vedi Russo e Grammatopoulou, 2003; Bhatarah et al., 2009) sia l’effetto di lunghezza opposto nelle liste di parole scelte a caso riportato in questo contributo. In contrasto con i modelli esistenti, la rappresentazione neuronale a lungo termine degli elementi gioca un ruolo cruciale nel nostro modello, e nessun meccanismo separato di memoria a breve termine è richiesto. In particolare, la probabilità di richiamo degli elementi in liste casuali aumenta con la dimensione della sua rappresentazione rispetto a quella di altri elementi, e questi elementi sono richiamati prima e sopprimono gli elementi con rappresentazioni più piccole (Romani et al., 2013). La probabilità media di richiamo dell’intero pool di elementi è comunque indipendente dalla dimensione media della rappresentazione, ma è correlata negativamente alla varianza della dimensione della rappresentazione nel pool (Katkov et al., presentato). Abbiamo quindi assunto che le parole più lunghe non hanno, in media, una rappresentazione più grande di quelle più corte, ma hanno collettivamente una varianza più alta della dimensione della rappresentazione. Questa ipotesi non ha attualmente alcuna giustificazione biologica diretta, ma ci ha permesso di conciliare l’apparente contraddizione tra le osservazioni sperimentali. In particolare, rende conto del classico effetto di lunghezza della parola, dove solo le parole con una data lunghezza sillabica sono presentate, e quindi la varianza della dimensione della rappresentazione aumenta con la lunghezza sillabica. Nelle liste con lunghezza sillabica mista, in alcune prove gli elementi con lunghezza sillabica più lunga hanno la più grande rappresentazione neuronale. Quando queste liste sono presentate, le parole più lunghe hanno una maggiore probabilità di essere richiamate, sopprimendo altre voci dall’essere richiamate, con conseguente lieve correlazione positiva tra la lunghezza sillabica di un elemento e la sua probabilità di richiamo.
I risultati presentati in questo contributo mostrano che la lunghezza della parola è un fattore prominente che influenza la facilità di richiamarla. Tuttavia, notiamo che le probabilità di richiamo mostrano ancora un’ampia distribuzione anche per parole di una data lunghezza, indicando che anche altre caratteristiche della parola, ancora sconosciute, contribuiscono alla probabilità di richiamare una parola.
Dichiarazione di conflitto di interessi
Gli autori dichiarano che la ricerca è stata condotta in assenza di qualsiasi relazione commerciale o finanziaria che possa essere interpretata come un potenziale conflitto di interessi.
Riconoscimenti
Siamo grati a M. Kahana per aver generosamente condiviso con noi i dati ottenuti nel suo laboratorio. Il laboratorio di Kahana è supportato dalla sovvenzione NIH MH55687. Misha Tsodyks è supportato da EU FP7 (Grant agreement 604102), Israeli Science Foundation e Foundation Adelis. Sandro Romani è sostenuto da Human Frontier Science Program long-term fellowship.
Baddeley, A. D. (1986). Memoria di lavoro. Oxford, Inghilterra: Oxford University Press.
Baddeley, A. D. (2003). Memoria di lavoro e linguaggio: una panoramica. J. Commun. Disord. 36, 189-208. doi: 10.1016/s0021-9924(03)00019-4
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Baddeley, A. D., Thomson, N., and Buchanan, M. (1975). La lunghezza delle parole e la struttura della memoria a breve termine. J. Verbal Learn. Verbal Behav. 14, 575-589. doi: 10.1016/s0022-5371(75)80045-4
CrossRef Full Text | Google Scholar
Bhatarah, P., Ward, G., Smith, J., and Hayes, L. (2009). Esaminare la relazione tra il richiamo libero e il richiamo seriale immediato: modelli simili di prova ed effetti simili di lunghezza della parola, tasso di presentazione e soppressione articolatoria. Mem. Cognit. 37, 689-713. doi: 10.3758/MC.37.5.689
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Burgess, N., and Hitch, G. (1999). Memoria per l’ordine seriale: un modello di rete del ciclo fonologico e dei suoi tempi. Psychol. Rev. 106, 551-581. doi: 10.1037//0033-295x.106.3.551
CrossRef Full Text | Google Scholar
Campoy, G. (2011). Interferenza retroattiva nella memoria a breve termine e l’effetto lunghezza della parola. Acta Psychol. (Amst) 138, 135-142. doi: 10.1016/j.actpsy.2011.05.016
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Hulme, C., Suprenant, A. M., Bireta, T. J., Stuart, G., e Neath, I. (2004). Abolire l’effetto lunghezza delle parole. J. Exp. Psychol. Learn. Mem. Cogn. 30, 98-106. doi: 10.1037/0278-7393.30.1.98
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Jalbert, A., Neath, I., Bireta, T. J., and Surprenant, A. M. (2011). Quando la lunghezza provoca l’effetto di lunghezza della parola? J. Exp. Psychol. Learn. Mem. Cogn. 37, 338-353. doi: 10.1037/a0021804
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Miller, J. F., Kahana, M. J., and Weidemann, C. T. (2012). Terminazione del richiamo nel richiamo libero. Mem. Cogn. 40, 540-550. doi: 10.3758/s13421-011-0178-9
CrossRef Full Text | Google Scholar
Neath, I., and Nairne, J. S. (1995). Effetti di lunghezza delle parole nella memoria immediata: la teoria del decadimento della traccia sovrascritta. Psychon. Bull. Rev. 2, 429-441. doi: 10.3758/bf03210981
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Page, M. P. A., and Norris, D. (1998). Il modello di primato: un nuovo modello di richiamo seriale immediato. Psychol. Rev. 105, 761-781. doi: 10.1037//0033-295x.105.4.761-781
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Romani, S., Pinkoviezky, I., Rubin, A., and Tsodyks, M. (2013). Leggi di scala del recupero della memoria associativa. Neural Comput. 25, 2523-2544. doi: 10.1162/NECO_a_00499
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Russo, R., e Grammatopoulou, N. (2003). La lunghezza delle parole e la soppressione articolatoria influenzano i compiti di richiamo a breve e lungo termine. Mem. Cognit. 31, 728-737. doi: 10.3758/bf03196111
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Tehan, G., and Tolan, G. A. (2007). Effetti della lunghezza delle parole nella memoria a lungo termine. J. Mem. Lang. 56, 35-48. doi: 10.1016/j.jml.2006.08.015
CrossRef Full Text | Google Scholar