Frontiers in Computational Neuroscience
Introduktion
Nyligen har vi föreslagit en mekanism för associativ informationsåtervinning som uttryckligen tar hänsyn till långsiktiga neuronala representationer av minnesobjekt (Romani et al., 2013). En av modellens grundläggande förutsägelser är existensen av ”lätta” och ”svåra” ord. Denna förutsägelse verifierades i vår analys av ett stort dataset av experiment med fri återkallelse som samlats in i Michael Kahanas labb, där vi visade att sannolikheten för att ord ska återkallas är konsekvent mellan godtyckligt valda grupper av försökspersoner (Katkov et al., submitted). Den naturliga fråga som dessa observationer ger upphov till är vilka egenskaper som är förutsägande för ords svårighet i återkallelseexperiment, i synnerhet vad om något är bidraget från ordlängden.
De flesta av de tidigare studierna av effekten av ordlängden använde listor som var specifikt sammansatta av antingen korta eller långa ord. I två tidigare studier där listor som bestod av omväxlande korta och långa ord användes, observerades ingen ordlängdseffekt (Hulme et al., 2004; Jalbert et al., 2011). I vårt nuvarande bidrag används free recall-paradigm och det bygger på ett mycket större dataset än tidigare studier. Vi rapporterar att när ord väljs slumpmässigt, oberoende av deras längd, återkallas långa ord bättre än korta, vilket verkar motsäga den klassiska ordlängdseffekten vid både seriell och fri återkallelse (Baddeley et al., 1975; Russo och Grammatopoulou, 2003; Tehan och Tolan, 2007; Bhatarah et al., 2009). Vi ger en möjlig lösning på denna motsägelse inom ramen för den associativa hämtningsmodellen i (Romani et al., 2013).
Material och metoder
Experimentella metoder
Den data som rapporteras i detta manuskript samlades in i M. Kahanas labb som en del av Penn Electrophysiology of Encoding and Retrieval Study (se Miller et al., 2012 för detaljer om experimenten). Här analyserade vi resultaten från de 141 deltagare (ålder 17-30 år) som genomförde experimentets första fas, som bestod av sju experimentella sessioner. Deltagarna fick sitt samtycke i enlighet med University of Pennsylvanias IRB-protokoll och kompenserades för sitt deltagande. Varje session bestod av 16 listor med 16 ord som presenterades en i taget på en datorskärm och varade ungefär 1,5 h. Varje studielista följdes av ett omedelbart test för fri erinran. Orden hämtades från en samling av 1638 ord. För varje lista fanns det en fördröjning på 1500 ms innan det första ordet dök upp på skärmen. Varje objekt var på skärmen i 3 000 ms, följt av ett jitterat 800-1200 ms interstimulusintervall (jämn fördelning). Efter det sista objektet i listan var det en fördröjning på 1200-1400 ms, varefter deltagaren fick 75 sekunder på sig att försöka minnas något av de nyss presenterade objekten. Alla försök användes; intrång och upprepningar togs bort från försöken.
Modellen
Vi antar att varje ord representeras av en slumpmässigt vald population av neuroner i det dedikerade minnesnätverket. Vi antar vidare att varje hämtad artikel fungerar som en intern ledtråd för nästa artikel i enlighet med likhetsmåttet mellan artiklarna, som definieras som en storleken på skärningspunkten mellan motsvarande populationer (antalet neuroner som representerar båda artiklarna). I enlighet med (Romani et al., 2013) tar vi hänsyn till den hämtningsprocess som direkt bestäms av minnesrepresentationer av objekten, utan att explicit simulera nätverksaktivitet. Dynamiken i hämtningen beskrivs av en sekvens av återkallade objekt. Det första objektet väljs slumpmässigt bland de presenterade, och varje efterföljande återkallat objekt väljs för att vara det objekt som har maximal likhet med det för närvarande återkallade objektet, utan att räkna med bara ”besökta” objekt (Romani et al., 2013). Återkallandet avslutas när återkallningsprocessen går in i en cykel och inga fler objekt kan återkallas.
För att efterlikna det experimentella protokollet (se ovan) genererade vi W = 1638 slumpmässiga binära mönster av längd N: {ξiw = 0; 1} med w = 1, … , W; i = 1, … , N anger neuronerna i nätverket, så att ξiw = 1 om neuron i deltar i kodningen av minnesobjektet w. Likheten mellan objekt w och w′ beräknas sedan som Sww′=∑i=1Nξiwξiw′. Mönsterkomponenterna för varje objekt drogs oberoende av varandra med sannolikheten pw att ξiw = 1 valdes på följande sätt: varje mönster tilldelades godtyckligt en stavelselängd lw = 1…4 så att fördelningen av lw över mönstren överensstämde med motsvarande fördelning över de ord som användes i försöket (fem ord med en stavelselängd som var större än fyra slogs ihop med ord med en stavelselängd på fyra). För mönster med given lw var motsvarande pw jämnt fördelade från 0,02 – 10-3lw till 0,02 + 10-3lw. Med detta val av mönsterstatistik beror det genomsnittliga antalet neuroner som representerar ett givet objekt inte på dess stavelselängd, medan variansen ökar med stavelselängden. Ordrepresentationerna var sedan fasta under hela det simulerade experimentet.
För varje simulerat återkallningsförsök valdes L = 16 objekt ut för presentation enligt två experimentella protokoll. För det första valdes objekten helt oberoende av varandra, som i Kahanas experiment. För det andra protokollet valdes objekt med samma lw slumpmässigt ut. Minnesprocessen simulerades som i (Romani et al., 2013). Det första återkallade objektet valdes slumpmässigt bland de presenterade. Efterföljande övergångar mellan återkallade objekt bestämdes av likhetsmatrisen S mellan dem, där varje element beräknades som antalet neuroner i skärningspunkten mellan motsvarande representationer: Sww′=∑i=1Nξiwξiw′. Närmare bestämt är nästa hämtade objekt det objekt som har den största likheten med det som nu hämtas, med undantag för det objekt som hämtades strax före det som nu hämtas. Återkallandet avslutas när hämtningsprocessen går in i en cykel och inga fler objekt kan hämtas.
Resultat
Vi analyserade ett stort dataset av experiment med fri återkallning som utfördes av 141 försökspersoner med 112 försök per försöksperson. Uppgifterna är insamlade i Michael Kahanas laboratorium. Listorna bestod av 16 ord som slumpmässigt valts ut från en pool av 1638 ord. Alla försök användes; intrång och upprepningar togs bort från försöken (totalt 15792 försök, se avsnitt Metoder). För varje ord beräknades dess totala återkallelsesannolikhet (Prec) som den andel av försöken som detta ord återkallades när det presenterades. Figur 1 visar fördelningen av (Prec) för alla ord med det givna antalet stavelser (svart) aggregerat från alla försök. Fördelningen av Prec är bred för alla ordlängder. Ändå växer den genomsnittliga sannolikheten för återkallande och dess varians monotont med antalet stavelser (korrelationskoefficienten är 0,15, p < 10-6).
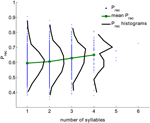
Figur 1. Sannolikheten för återkallande av ord med olika antal stavelser (blå prickar), fördelningen av sannolikheten för återkallande (svart) och medelvärdet för sannolikheten för återkallande (grönt) beräknat från experimentella data. Korrelationskoefficienten mellan antalet stavelser och återkallelsesannolikheten är 0,15, p < 10-6).
Detta resultat tycks motsäga den klassiska ordlängdseffekten, där listor med korta ord visade sig återkallas bättre än listor med längre ord (Baddeley m.fl., 1975; Russo och Grammatopoulou, 2003; Tehan och Tolan, 2007; Bhatarah m.fl., 2009). För att testa om båda dessa effekter kan förklaras av vår föreslagna mekanism för återvinning simulerade vi modellen genom att imitera experimentella paradigm i två tillstånd – fri återkallelse med listor bestående av korta/långa ord och slumpmässiga listor (se Metod). Det överraskande resultatet framkom: prestationen i uppgiften om fri återkallelse beror på det experimentella paradigmet – vid återkallelse av en slumpmässig blandning av orelaterade ord är längre ord statistiskt sett lättare att återkalla, medan kortare ord är lättare att återkalla i listor som är sammansatta av ord med ett fast antal stavelser (figur 2).
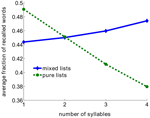
Figur 2. Genomsnittlig andel återkallade ord som en funktion av antalet stavelser i modellen. Rena listor är sammansatta med hjälp av endast ord med samma antal stavelser. Blandade listor är sammansatta av hela poolen av ord.
De flesta förklaringar av klassiska ordlängdseffekter utgår från att den totala längden på presenterade stimuli är negativt korrelerad med antalet återkallade ord. För att testa om detta påstående stöds av data beräknade vi korrelationen mellan antalet stavelser i presenterade listor och antalet återkallade ord. Vi fann praktiskt taget ingen korrelation (korrelationskoefficienten är 0,004 och skiljer sig inte signifikant från 0, p = 0,67).
Diskussion
Wordlängdseffekten, dvs. observationen att listor med korta ord återkallas bättre än listor med långa ord (Baddeley et al., 1975), anses vara ett av de viktigaste fenomenen i teorierna om korttidsminnet (Campoy, 2011; Jalbert et al., 2011). Här rapporterar vi att vid fri återkallelse av orelaterade ord, där korta och långa ord blandas slumpmässigt, har långa ord högre återkallelsesannolikhet än korta ord, vilket verkar motsäga ordlängdseffekten.
Den klassiska ordlängdseffekten förklaras traditionellt med antingen ökad komplexitet hos längre objekt (Neath och Nairne, 1995), eller ökad repetitionstid för längre objekt (Baddeley, 1986, 2003; Page och Norris, 1998; Burgess och Hitch, 1999). Den första redovisningen tyder på att kortare ord generellt sett är lättare att minnas, vilket inte är förenligt med vår observation. Enligt den andra förklaringen kan fler av korta ord repeteras, på grund av kortare repetitionstid, och därför återkallas fler av dem. Denna förklaring specificerar inte i vilken ordning man skulle repetera presenterade ord, men den antyder en negativ korrelation mellan den totala längden på presenterade objekt och antalet återkallade ord, medan det inte finns någon sådan korrelation i data.
Här visar vi att vår nyligen föreslagna mekanism för associativ hämtning potentiellt kan förklara både den klassiska ordlängdseffekten (som också förekommer i experiment med fri återkallelse, se Russo och Grammatopoulou, 2003, Bhatarah m.fl., 2009) och den motsatta längdeffekten i listor över slumpmässigt utvalda ord som rapporteras i detta bidrag. Till skillnad från befintliga modeller spelar långsiktig neuronal representation av objekt en avgörande roll i vår modell, och det krävs ingen separat mekanism för korttidsminnet. I synnerhet ökar sannolikheten för återkallande av objekt i slumpmässiga listor med storleken på dess representation i förhållande till andra objekt, och dessa objekt återkallas tidigare och undertrycker objekt med mindre representationer (Romani et al., 2013). Den genomsnittliga återkallelsesannolikheten för hela gruppen av objekt är dock oberoende av den genomsnittliga representationsstorleken men förhåller sig negativt till variansen i representationsstorlek över gruppen (Katkov et al., submitted). Vi antog därför att längre ord inte i genomsnitt har en större representation än kortare ord, utan att de kollektivt har en högre varians i representationsstorlek. Detta antagande har för närvarande inget direkt biologiskt berättigande, men gjorde det möjligt för oss att förena den skenbara motsättningen mellan de experimentella observationerna. Det förklarar särskilt den klassiska ordlängdseffekten, där endast ord med en viss stavelselängd presenteras och variansen i representationsstorlek därför ökar med stavelselängden. I listor med blandad stavningslängd har objekt med längre stavningslängd i vissa försök den största neuronala representationen. När dessa listor presenteras har längre ord större sannolikhet att återkallas, vilket gör att andra ord inte återkallas, vilket resulterar i en mild positiv korrelation mellan ett ords stavningslängd och dess återkallelsesannolikhet.
Resultaten som presenteras i detta bidrag visar att ordets längd är en framträdande faktor som påverkar hur lätt det är att återkalla det. Vi noterar dock att återkallelsesannolikheterna fortfarande uppvisar en stor spridning även för ord av given längd, vilket tyder på att andra, ännu okända, ordegenskaper också bidrar till sannolikheten att återkalla ett ord.
Intressekonfliktförklaring
Författarna förklarar att forskningen utfördes i avsaknad av kommersiella eller ekonomiska relationer som skulle kunna tolkas som en potentiell intressekonflikt.
Acknowledgments
Vi är tacksamma mot M. Kahana för att han generöst delade med sig av de data som erhållits i hans laboratorium till oss. Kahanas laboratorium stöds av NIH-anslaget MH55687. Misha Tsodyks stöds av EU FP7 (Grant agreement 604102), Israeli Science Foundation och Foundation Adelis. Sandro Romani stöds av Human Frontier Science Program long-term fellowship.
Baddeley, A. D. (1986). Arbetsminne. Oxford, England: Oxford University Press.
Baddeley, A. D. (2003). Arbetsminne och språk: en översikt. J. Commun. Disord. 36, 189-208. doi: 10.1016/s0021-9924(03)00019-4
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Baddeley, A. D., Thomson, N. och Buchanan, M. (1975). Ordlängd och strukturen i korttidsminnet. J. Verbal Learn. Verbal Behav. 14, 575-589. doi: 10.1016/s0022-5371(75)80045-4
CrossRef Full Text | Google Scholar
Bhatarah, P., Ward, G., Smith, J. och Hayes, L. (2009). Undersökning av förhållandet mellan fri återkallelse och omedelbar seriell återkallelse: liknande mönster av repetition och liknande effekter av ordlängd, presentationshastighet och artikulatorisk undertryckning. Mem. Cognit. 37, 689-713. doi: 10.3758/MC.37.5.689
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Burgess, N., and Hitch, G. (1999). Minne för seriell ordning: en nätverksmodell av den fonologiska slingan och dess timing. Psychol. Rev. 106, 551-581. doi: 10.1037//0033-295x.106.3.551
CrossRef Full Text | Google Scholar
Campoy, G. (2011). Retroaktiv störning i korttidsminnet och ordlängdseffekten. Acta Psychol. (Amst) 138, 135-142. doi: 10.1016/j.actpsy.2011.05.016
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Hulme, C., Suprenant, A. M., Bireta, T. J., Stuart, G. och Neath, I. (2004). Att avskaffa ordlängdseffekten. J. Exp. Psychol. Learn. Mem. Cogn. 30, 98-106. doi: 10.1037/0278-7393.30.1.98
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Jalbert, A., Neath, I., Bireta, T. J., and Surprenant, A. M. (2011). När orsakar längden ordlängdseffekten?. J. Exp. Psychol. Learn. Mem. Cogn. 37, 338-353. doi: 10.1037/a0021804
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Miller, J. F., Kahana, M. J. och Weidemann, C. T. (2012). Upphörande av återkallande vid fritt återkallande. Mem. Cogn. 40, 540-550. doi: 10.3758/s13421-011-0178-9
CrossRef Full Text | Google Scholar
Neath, I., and Nairne, J. S. (1995). Word-length effects in immediate memory: overwriting trace decay theory. Psychon. Bull. Rev. 2, 429-441. doi: 10.3758/bf03210981
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Page, M. P. A., and Norris, D. (1998). Primatmodellen: en ny modell för omedelbar serieåterkallelse. Psychol. Rev. 105, 761-781. doi: 10.1037//0033-295x.105.4.761-781
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Romani, S., Pinkoviezky, I., Rubin, A. och Tsodyks, M. (2013). Skalningslagar för associerande minnesåterhämtning. Neural Comput. 25, 2523-2544. doi: 10.1162/NECO_a_00499
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Russo, R., and Grammatopoulou, N. (2003). Ordlängd och artikulatorisk undertryckning påverkar kortsiktiga och långsiktiga minnesuppgifter. Mem. Cognit. 31, 728-737. doi: 10.3758/bf03196111
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Tehan, G., and Tolan, G. A. (2007). Effekter av ordlängd i långtidsminnet. J. Mem. Lang. 56, 35-48. doi: 10.1016/j.jml.2006.08.015
CrossRef Full Text | Google Scholar