Frontiers in Computational Neuroscience
Introduction
Vor kurzem haben wir einen Mechanismus des assoziativen Informationsabrufs vorgeschlagen, der explizit die langfristigen neuronalen Repräsentationen von Gedächtnisinhalten berücksichtigt (Romani et al., 2013). Eine der grundlegenden Vorhersagen des Modells ist die Existenz von „leichten“ und „schwierigen“ Wörtern. Diese Vorhersage wurde in unserer Analyse eines großen Datensatzes von Experimenten zum freien Abruf verifiziert, die im Labor von Michael Kahana gesammelt wurden, wo wir zeigten, dass die Wahrscheinlichkeit, dass Wörter abgerufen werden, zwischen beliebig ausgewählten Gruppen von Probanden konsistent ist (Katkov et al., eingereicht). Die natürliche Frage, die sich aus diesen Beobachtungen ergibt, ist, welche Merkmale für die Wortschwierigkeit in Gedächtnisexperimenten prädiktiv sind, insbesondere, welchen Beitrag, wenn überhaupt, die Wortlänge leistet.
Die meisten früheren Studien zum Wortlängeneffekt verwendeten Listen, die speziell aus kurzen oder langen Wörtern zusammengesetzt waren. In zwei früheren Studien, in denen Listen verwendet wurden, die abwechselnd aus kurzen und langen Wörtern bestanden, wurde kein Wortlängeneffekt beobachtet (Hulme et al., 2004; Jalbert et al., 2011). Unser aktueller Beitrag verwendet das Paradigma des freien Abrufs und basiert auf einem viel größeren Datensatz als frühere Studien. Wir berichten, dass bei einer zufälligen Auswahl von Wörtern, unabhängig von ihrer Länge, lange Wörter besser erinnert werden als kurze, was im scheinbaren Widerspruch zum klassischen Wortlängeneffekt sowohl beim seriellen als auch beim freien Abruf steht (Baddeley et al., 1975; Russo und Grammatopoulou, 2003; Tehan und Tolan, 2007; Bhatarah et al., 2009). Wir bieten eine mögliche Auflösung dieses Widerspruchs im Rahmen des assoziativen Abrufmodells von (Romani et al., 2013).
Materialien und Methoden
Experimentelle Methoden
Die in diesem Manuskript berichteten Daten wurden im Labor von M. Kahana im Rahmen der Penn Electrophysiology of Encoding and Retrieval Study erhoben (siehe Miller et al., 2012 für Details der Experimente). Hier wurden die Ergebnisse von 141 Teilnehmern (17-30 Jahre) analysiert, die die erste Phase des Experiments, bestehend aus sieben experimentellen Sitzungen, abgeschlossen hatten. Die Teilnehmer hatten ihr Einverständnis gemäß dem IRB-Protokoll der Universität Pennsylvania gegeben und wurden für ihre Teilnahme entschädigt. Jede Sitzung bestand aus 16 Listen mit 16 Wörtern, die nacheinander auf einem Computerbildschirm präsentiert wurden, und dauerte ca. 1,5 h. Auf jede Studienliste folgte ein sofortiger freier Erinnerungstest. Die Wörter wurden aus einem Pool von 1638 Wörtern ausgewählt. Bei jeder Liste gab es eine Verzögerung von 1500 ms, bevor das erste Wort auf dem Bildschirm erschien. Jedes Item war 3000 ms lang auf dem Bildschirm zu sehen, gefolgt von einem gejitterten Interstimulusintervall von 800-1200 ms (gleichmäßige Verteilung). Nach dem letzten Item in der Liste gab es eine Verzögerung von 1200-1400 ms, nach der der Teilnehmer 75 Sekunden Zeit hatte, um zu versuchen, sich an eines der soeben präsentierten Items zu erinnern. Alle Versuche wurden verwendet; Eindringlinge und Wiederholungen wurden aus den Versuchen entfernt.
Das Modell
Wir gehen davon aus, dass jedes Wort durch eine zufällig ausgewählte Population von Neuronen in einem speziellen Gedächtnisnetzwerk repräsentiert wird. Wir gehen ferner davon aus, dass jeder abgerufene Begriff als interner Hinweis für den nächsten Begriff dient, und zwar entsprechend dem Ähnlichkeitsmaß zwischen den Begriffen, das als Größe der Schnittmenge zwischen den entsprechenden Populationen definiert ist (die Anzahl der Neuronen, die beide Begriffe repräsentieren). In Anlehnung an (Romani et al., 2013) betrachten wir den Abrufprozess, der direkt durch die Gedächtnisrepräsentationen der Items bestimmt wird, ohne die Netzwerkaktivität explizit zu simulieren. Die Dynamik des Abrufs wird durch eine Abfolge von abgerufenen Items beschrieben. Das erste Item wird zufällig unter den präsentierten Items ausgewählt, und jedes nachfolgend abgerufene Item wird so ausgewählt, dass es eine maximale Ähnlichkeit mit dem aktuell abgerufenen Item aufweist, wobei nur „besuchte“ Items nicht mitgezählt werden (Romani et al., 2013). Der Abruf wird beendet, wenn der Abrufprozess in einen Zyklus eintritt und keine weiteren Elemente abgerufen werden können.
Um das Versuchsprotokoll (siehe oben) nachzuahmen, haben wir W = 1638 zufällige binäre Muster der Länge N erzeugt: {ξiw = 0; 1} mit w = 1, … , W; i = 1, … , N bezeichnet die Neuronen im Netzwerk, so dass ξiw = 1 ist, wenn Neuron i an der Kodierung des Gedächtniseintrags w beteiligt ist. Die Ähnlichkeit zwischen den Elementen w und w′ wird dann berechnet als Sww′=∑i=1Nξiwξiw′. Die Musterkomponenten für jedes Item wurden unabhängig voneinander mit der Wahrscheinlichkeit pw von ξiw = 1 gezogen und folgendermaßen ausgewählt: Jedem Muster wurde willkürlich eine Silbenlänge lw = 1…4 zugewiesen, so dass die Verteilung von lw über die Muster der entsprechenden Verteilung über die im Experiment verwendeten Wörter entsprach (fünf Wörter mit einer Silbenlänge von mehr als vier wurden mit denen der Länge vier kombiniert). Für Muster mit gegebenen lw waren die entsprechenden pw äquidistant verteilt von 0,02 – 10-3lw bis 0,02 + 10-3lw. Bei dieser Wahl der Musterstatistik hängt die durchschnittliche Anzahl der Neuronen, die ein bestimmtes Item repräsentieren, nicht von seiner Silbenlänge ab, während die Varianz mit der Silbenlänge zunimmt. Die Wortrepräsentationen wurden dann während des gesamten simulierten Experiments fixiert.
Für jeden simulierten Erinnerungsversuch wurden L = 16 Items für die Präsentation nach zwei experimentellen Protokollen ausgewählt. Im ersten Protokoll wurden die Items völlig unabhängig voneinander ausgewählt, wie im Experiment von Kahana. Für das zweite Protokoll wurden Items mit demselben lw zufällig ausgewählt. Der Abrufprozess wurde wie in (Romani et al., 2013) simuliert. Das erste abgerufene Item wurde zufällig aus den präsentierten Items ausgewählt. Nachfolgende Übergänge zwischen abgerufenen Items wurden durch die Ähnlichkeitsmatrix S zwischen ihnen bestimmt, wobei jedes Element der Matrix als die Anzahl der Neuronen in der Schnittmenge zwischen den entsprechenden Repräsentationen berechnet wurde: Sww′=∑i=1Nξiwξiw′. Genauer gesagt, ist das nächste abgerufene Element dasjenige, das die größte Ähnlichkeit mit dem aktuell abgerufenen Element aufweist, wobei das Element, das kurz vor dem aktuellen abgerufen wurde, ausgeschlossen wird. Der Abruf wird beendet, wenn der Abrufprozess in einen Zyklus eintritt und keine weiteren Elemente mehr abgerufen werden können.
Ergebnisse
Wir analysierten einen großen Datensatz von Experimenten zum freien Abruf, die von 141 Probanden mit 112 Versuchen pro Proband durchgeführt wurden. Die Daten wurden im Labor von Michael Kahana gesammelt. Die Listen bestanden aus 16 Wörtern, die zufällig aus einem Pool von 1638 Wörtern ausgewählt wurden. Es wurden alle Versuche verwendet; Eingriffe und Wiederholungen wurden aus den Versuchen entfernt (insgesamt 15792 Versuche, siehe Abschnitt Methoden). Für jedes Wort wurde die Gesamterinnerungswahrscheinlichkeit (Prec) berechnet, d. h. der Anteil der Versuche, in denen das Wort bei seiner Präsentation erinnert wurde. Abbildung 1 zeigt die Verteilung von (Prec) für alle Wörter mit der gegebenen Anzahl von Silben (schwarz), aggregiert aus allen Versuchen. Die Verteilung von Prec ist für alle Wortlängen breit. Dennoch wachsen die mittlere Wiedererkennungswahrscheinlichkeit und ihre Varianz monoton mit der Anzahl der Silben (Korrelationskoeffizient ist 0,15, p < 10-6).
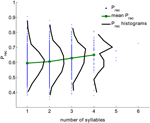
Abbildung 1. Wiedererkennungswahrscheinlichkeit für Wörter mit unterschiedlicher Silbenzahl (blaue Punkte), die Verteilung der Wiedererkennungswahrscheinlichkeiten (schwarz) und der Mittelwert der Wiedererkennungswahrscheinlichkeit (grün), berechnet aus den experimentellen Daten. Der Korrelationskoeffizient zwischen der Anzahl der Silben und der Abrufwahrscheinlichkeit beträgt 0,15, p < 10-6).
Dieses Ergebnis scheint dem klassischen Wortlängeneffekt zu widersprechen, bei dem Listen mit kurzen Wörtern nachweislich besser abgerufen werden als Listen mit längeren Wörtern (Baddeley et al., 1975; Russo und Grammatopoulou, 2003; Tehan und Tolan, 2007; Bhatarah et al., 2009). Um zu prüfen, ob diese beiden Effekte durch den von uns vorgeschlagenen Abrufmechanismus erklärt werden können, simulierten wir das Modell, indem wir experimentelle Paradigmen in zwei Bedingungen nachahmten – freier Abruf mit Listen, die aus kurzen/langen Wörtern zusammengesetzt waren, und Zufallslisten (siehe Methoden). Das überraschende Ergebnis: Die Leistung im freien Abruf hängt vom experimentellen Paradigma ab – beim Abruf einer zufälligen Mischung nicht verwandter Wörter sind längere Wörter statistisch gesehen leichter abrufbar, während bei Listen, die aus Wörtern mit fester Silbenzahl bestehen, kürzere Wörter leichter abrufbar sind (Abbildung 2).
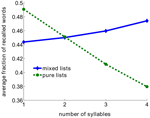
Abbildung 2. Durchschnittlicher Anteil der abgerufenen Wörter als Funktion der Anzahl der Silben im Modell. Reine Listen werden nur aus Wörtern mit der gleichen Silbenzahl zusammengestellt. Gemischte Listen werden aus dem gesamten Wortschatz zusammengestellt.
Die meisten Erklärungen der klassischen Wortlängeneffekte gehen davon aus, dass die Gesamtlänge der dargebotenen Stimuli negativ mit der Anzahl der abgerufenen Wörter korreliert ist. Um zu prüfen, ob diese Aussage durch die Daten gestützt wird, haben wir die Korrelation zwischen der Anzahl der Silben in den präsentierten Listen und der Anzahl der abgerufenen Wörter berechnet. Wir fanden praktisch keine Korrelation (der Korrelationskoeffizient beträgt 0,004 und ist nicht signifikant von 0 verschieden, p = 0,67).
Diskussion
Der Wortlängeneffekt, d.h. die Beobachtung, dass Listen mit kurzen Wörtern besser erinnert werden als Listen mit langen Wörtern (Baddeley et al., 1975), gilt als eines der Schlüsselphänomene in den Theorien des Kurzzeitgedächtnisses (Campoy, 2011; Jalbert et al., 2011). Hier berichten wir, dass beim freien Abruf von nicht verwandten Wörtern, bei denen kurze und lange Wörter zufällig gemischt werden, lange Wörter eine höhere Abrufwahrscheinlichkeit haben als kurze, was in scheinbarem Widerspruch zum Wortlängeneffekt steht.
Der klassische Wortlängeneffekt wird traditionell entweder durch eine erhöhte Komplexität längerer Items (Neath und Nairne, 1995) oder durch eine erhöhte Wiederholungszeit längerer Items (Baddeley, 1986, 2003; Page und Norris, 1998; Burgess und Hitch, 1999) erklärt. Die erste Erklärung legt nahe, dass kürzere Wörter generell leichter abrufbar sind, was mit unseren Beobachtungen nicht vereinbar ist. Die zweite Erklärung besagt, dass aufgrund der kürzeren Wiederholungszeit mehr kurze Wörter geübt werden können und daher mehr von ihnen abgerufen werden. Diese Erklärung gibt nicht an, in welcher Reihenfolge man die präsentierten Wörter proben würde, aber sie legt eine negative Korrelation zwischen der Gesamtlänge der präsentierten Elemente und der Anzahl der abgerufenen Wörter nahe, während eine solche Korrelation in den Daten nicht existiert.
Hier zeigen wir, dass unser kürzlich vorgeschlagener Mechanismus des assoziativen Abrufs sowohl den klassischen Wortlängeneffekt (der auch in Experimenten zum freien Abruf auftritt, siehe Russo und Grammatopoulou, 2003; Bhatarah et al., 2009) als auch den entgegengesetzten Längeneffekt in Listen zufällig ausgewählter Wörter erklären kann, über den in diesem Beitrag berichtet wird. Im Gegensatz zu bestehenden Modellen spielt in unserem Modell die neuronale Langzeitrepräsentation von Items eine entscheidende Rolle, und es ist kein separater Kurzzeitgedächtnismechanismus erforderlich. Insbesondere steigt die Abrufwahrscheinlichkeit von Elementen in Zufallslisten mit der Größe ihrer Repräsentation im Vergleich zu der anderer Elemente, und diese Elemente werden früher abgerufen und unterdrücken die Elemente mit kleineren Repräsentationen (Romani et al., 2013). Die durchschnittliche Abrufwahrscheinlichkeit des gesamten Pools von Items ist jedoch unabhängig von der durchschnittlichen Repräsentationsgröße, hängt aber negativ mit der Varianz der Repräsentationsgröße im Pool zusammen (Katkov et al., eingereicht). Wir haben daher angenommen, dass längere Wörter nicht im Durchschnitt eine größere Repräsentation haben als kürzere, sondern insgesamt eine höhere Varianz der Repräsentationsgröße aufweisen. Für diese Annahme gibt es derzeit keine direkte biologische Begründung, aber sie ermöglichte es uns, den scheinbaren Widerspruch zwischen den experimentellen Beobachtungen in Einklang zu bringen. Sie erklärt insbesondere den klassischen Wortlängeneffekt, bei dem nur Wörter mit einer bestimmten Silbenlänge präsentiert werden und daher die Varianz der Darstellungsgröße mit der Silbenlänge zunimmt. In Listen mit gemischter Silbenlänge haben in einigen Versuchen die Wörter mit längerer Silbenlänge die größte neuronale Repräsentation. Wenn diese Listen präsentiert werden, haben längere Wörter eine größere Wahrscheinlichkeit, abgerufen zu werden, und verdrängen andere Elemente aus dem Gedächtnis, was zu einer leichten positiven Korrelation zwischen der Silbenlänge eines Elements und seiner Abrufwahrscheinlichkeit führt.
Die in diesem Beitrag vorgestellten Ergebnisse zeigen, dass die Länge des Wortes ein wichtiger Faktor ist, der die Leichtigkeit des Abrufs beeinflusst. Wir stellen jedoch fest, dass die Abrufwahrscheinlichkeiten auch bei Wörtern mit einer bestimmten Länge eine breite Streuung aufweisen, was darauf hindeutet, dass andere, noch unbekannte Wortmerkmale ebenfalls zur Abrufwahrscheinlichkeit eines Wortes beitragen.
Erklärung zu Interessenkonflikten
Die Autoren erklären, dass die Forschung in Abwesenheit jeglicher kommerzieller oder finanzieller Beziehungen durchgeführt wurde, die als potenzieller Interessenkonflikt ausgelegt werden könnten.
Danksagungen
Wir sind M. Kahana dankbar, dass er uns großzügig die in seinem Labor gewonnenen Daten zur Verfügung stellt. Das Labor von Kahana wird vom NIH-Stipendium MH55687 unterstützt. Misha Tsodyks wird von der EU FP7 (Grant agreement 604102), der Israeli Science Foundation und der Foundation Adelis unterstützt. Sandro Romani wird durch ein Langzeitstipendium des Human Frontier Science Program unterstützt.
Baddeley, A. D. (1986). Working Memory. Oxford, England: Oxford University Press.
Baddeley, A. D. (2003). Arbeitsgedächtnis und Sprache: ein Überblick. J. Commun. Disord. 36, 189-208. doi: 10.1016/s0021-9924(03)00019-4
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Baddeley, A. D., Thomson, N., and Buchanan, M. (1975). Wortlänge und die Struktur des Kurzzeitgedächtnisses. J. Verbal Learn. Verbal Behav. 14, 575-589. doi: 10.1016/s0022-5371(75)80045-4
CrossRef Full Text | Google Scholar
Bhatarah, P., Ward, G., Smith, J., and Hayes, L. (2009). Untersuchung der Beziehung zwischen freiem Abruf und unmittelbarem seriellen Abruf: ähnliche Muster des Wiederholens und ähnliche Effekte von Wortlänge, Präsentationsrate und artikulatorischer Unterdrückung. Mem. Cognit. 37, 689-713. doi: 10.3758/MC.37.5.689
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Burgess, N., and Hitch, G. (1999). Memory for serial order: a network model of the phonological loop and its timing. Psychol. Rev. 106, 551-581. doi: 10.1037//0033-295x.106.3.551
CrossRef Full Text | Google Scholar
Campoy, G. (2011). Retroaktive Interferenz im Kurzzeitgedächtnis und der Wortlängeneffekt. Acta Psychol. (Amst) 138, 135-142. doi: 10.1016/j.actpsy.2011.05.016
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Hulme, C., Suprenant, A. M., Bireta, T. J., Stuart, G., and Neath, I. (2004). Die Abschaffung des Wortlängeneffekts. J. Exp. Psychol. Learn. Mem. Cogn. 30, 98-106. doi: 10.1037/0278-7393.30.1.98
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Jalbert, A., Neath, I., Bireta, T. J., and Surprenant, A. M. (2011). Wann verursacht die Länge den Wortlängeneffekt? J. Exp. Psychol. Learn. Mem. Cogn. 37, 338-353. doi: 10.1037/a0021804
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Miller, J. F., Kahana, M. J., and Weidemann, C. T. (2012). Recall termination in free recall. Mem. Cogn. 40, 540-550. doi: 10.3758/s13421-011-0178-9
CrossRef Full Text | Google Scholar
Neath, I., and Nairne, J. S. (1995). Wortlängeneffekte im unmittelbaren Gedächtnis: Überschreibung der Spurenabfalltheorie. Psychon. Bull. Rev. 2, 429-441. doi: 10.3758/bf03210981
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Page, M. P. A., and Norris, D. (1998). Das Primacy-Modell: ein neues Modell des unmittelbaren Serienabrufs. Psychol. Rev. 105, 761-781. doi: 10.1037//0033-295x.105.4.761-781
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Romani, S., Pinkoviezky, I., Rubin, A., and Tsodyks, M. (2013). Skalierungsgesetze des assoziativen Speicherabrufs. Neural Comput. 25, 2523-2544. doi: 10.1162/NECO_a_00499
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Russo, R., and Grammatopoulou, N. (2003). Wortlänge und artikulatorische Unterdrückung beeinflussen Kurzzeit- und Langzeit-Erinnerungsaufgaben. Mem. Cognit. 31, 728-737. doi: 10.3758/bf03196111
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Tehan, G., and Tolan, G. A. (2007). Wortlängeneffekte im Langzeitgedächtnis. J. Mem. Lang. 56, 35-48. doi: 10.1016/j.jml.2006.08.015
CrossRef Full Text | Google Scholar