Frontiers in Computational Neuroscience
Úvod
Nedávno jsme navrhli mechanismus asociativního získávání informací, který explicitně zohledňuje dlouhodobé neuronální reprezentace paměťových položek (Romani et al., 2013). Jednou ze základních předpovědí tohoto modelu je existence „snadných“ a „obtížných“ slov. Tuto předpověď jsme ověřili při analýze rozsáhlého souboru dat z experimentů s volným vybavováním shromážděných v laboratoři Michaela Kahany, kde jsme ukázali, že pravděpodobnosti vybavování slov jsou konzistentní mezi libovolně zvolenými skupinami subjektů (Katkov et al., submitted). Přirozenou otázkou, kterou tato pozorování vyvolávají, je, jaké vlastnosti jsou prediktivní pro obtížnost slov ve vzpomínkových experimentech, zejména jaký je případný příspěvek délky slov.
Většina předchozích studií efektu délky slov používala seznamy, které byly specificky složeny buď z krátkých, nebo dlouhých slov. Ve dvou předchozích studiích, kde byly použity seznamy složené střídavě z krátkých a dlouhých slov, nebyl efekt délky slova pozorován (Hulme et al., 2004; Jalbert et al., 2011). Náš současný příspěvek využívá paradigma volného vzpomínání a vychází z mnohem většího souboru dat než předchozí studie. Uvádíme, že při náhodném výběru slov bez ohledu na jejich délku jsou dlouhá slova vybavována lépe než krátká, což je ve zdánlivém rozporu s klasickým efektem délky slova při sériovém i volném vybavování (Baddeley et al., 1975; Russo a Grammatopoulou, 2003; Tehan a Tolan, 2007; Bhatarah et al., 2009). Nabízíme možné řešení tohoto rozporu v rámci asociativního modelu vyhledávání (Romani et al., 2013).
Materiál a metody
Experimentální metody
Údaje uvedené v tomto rukopise byly shromážděny v laboratoři M. Kahana v rámci Penn Electrophysiology of Encoding and Retrieval Study (podrobnosti o experimentech viz Miller et al., 2012). Zde jsme analyzovali výsledky 141 účastníků (ve věku 17-30 let), kteří absolvovali první fázi experimentu sestávající ze sedmi experimentálních sezení. Účastníci získali souhlas v souladu s protokolem IRB Pensylvánské univerzity a za svou účast dostali kompenzaci. Každé sezení se skládalo z 16 seznamů po 16 slovech prezentovaných postupně na obrazovce počítače a trvalo přibližně 1,5 h. Po každém studijním seznamu následoval okamžitý test volné paměti. Slova byla vybrána ze souboru 1638 slov. U každého seznamu byla prodleva 1500 ms, než se na obrazovce objevilo první slovo. Každá položka byla na obrazovce po dobu 3000 ms, poté následoval interval mezi jednotlivými stimuly 800-1200 ms (rovnoměrné rozložení). Po poslední položce seznamu následovala prodleva 1200-1400 ms, po níž měl účastník 75 s na to, aby se pokusil vybavit si některou z právě zobrazených položek. Byly použity všechny pokusy; intruze a opakování byly z pokusů odstraněny.
Model
Předpokládáme, že každé slovo je reprezentováno náhodně vybranou populací neuronů ve vyhrazené paměťové síti. Dále předpokládáme, že každá načtená položka funguje jako vnitřní vodítko pro další položku podle míry podobnosti mezi položkami, která je definována jako velikost průsečíku mezi odpovídajícími populacemi (počet neuronů, které reprezentují obě položky). V návaznosti na (Romani et al., 2013) uvažujeme proces vyhledávání, který je přímo určen paměťovými reprezentacemi položek, aniž bychom explicitně simulovali aktivitu sítě. Dynamika vyhledávání je popsána posloupností vyvolaných položek. První z nich je náhodně vybrána mezi prezentovanými a každá další vyvolaná položka je vybrána tak, aby byla tou, která má maximální podobnost s aktuálně vyvolanou položkou, přičemž se nepočítá právě „navštívená“ položka (Romani et al., 2013). Vyvolávání je ukončeno, když proces vyvolávání vstoupí do cyklu a nelze vyvolat žádné další položky.
Pro napodobení experimentálního protokolu (viz výše) jsme vygenerovali W = 1638 náhodných binárních vzorů o délce N: {ξiw = 0; 1}, přičemž w = 1, … , W; i = 1, … , N označuje neurony v síti tak, že ξiw = 1, pokud se neuron i podílí na kódování paměťové položky w. Podobnost mezi položkami w a w′ se pak vypočítá jako Sww′=∑i=1Nξiwξiw′. Složky vzoru pro každou položku byly losovány nezávisle s pravděpodobností pw ξiw = 1 zvolenou následujícím způsobem: každému vzoru byla libovolně přiřazena slabičná délka lw = 1…4 tak, aby rozložení lw napříč vzory odpovídalo odpovídajícímu rozložení napříč slovy použitými v experimentu (pět slov se slabičnou délkou větší než čtyři bylo spojeno se slovy o délce čtyři). Pro vzory s daným lw byly odpovídající pw rozloženy ekvidistantně od 0,02 – 10-3lw do 0,02 + 10-3lw. Při této volbě statistiky vzorů nezávisí průměrný počet neuronů reprezentujících danou položku na její slabičné délce, zatímco rozptyl se slabičnou délkou roste. Reprezentace slov pak byly po celou dobu simulovaného experimentu fixní.
Pro každý simulovaný vzpomínkový pokus bylo vybráno L = 16 položek k prezentaci podle dvou experimentálních protokolů. U prvního byly položky vybírány zcela nezávisle, stejně jako v Kahanově experimentu. U druhého protokolu byly náhodně vybrány položky se stejným lw. Proces vybavování byl simulován stejně jako v (Romani et al., 2013). První vzpomínaná položka byla náhodně vybrána mezi předloženými položkami. Následné přechody mezi vyvolanými položkami byly určeny maticí podobnosti S mezi nimi, jejíž každý prvek byl vypočten jako počet neuronů v průsečíku mezi odpovídajícími reprezentacemi: Sww′=∑i=1Nξiwξiw′. Přesněji řečeno, další načtená položka je ta, která má maximální podobnost s aktuálně načtenou položkou, s výjimkou položky, která byla načtena těsně před aktuální položkou. Vyvolávání je ukončeno, když proces vyvolávání vstoupí do cyklu a nelze vyvolat žádné další položky.
Výsledky
Analyzovali jsme rozsáhlý soubor dat z experimentů s volným vyvoláváním provedených 141 subjekty se 112 pokusy na subjekt. Data byla shromážděna v laboratoři Michaela Kahany. Seznamy byly složeny z 16 slov náhodně vybraných ze souboru 1638 slov. Byly použity všechny pokusy; intruze a opakování byly z pokusů odstraněny (celkem 15792 pokusů, viz oddíl Metody). Pro každé slovo byla vypočtena jeho celková pravděpodobnost vyvolání (Prec) jako podíl pokusů, kdy bylo toto slovo vyvoláno, když bylo prezentováno. Obrázek 1 ukazuje rozložení (Prec) pro všechna slova s daným počtem slabik (černě) agregovaná ze všech pokusů. Rozložení Prec je široké pro všechny délky slov. Nicméně průměrná pravděpodobnost vyvolání a její rozptyl monotónně rostou s počtem slabik (korelační koeficient je 0,15, p < 10-6).
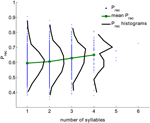
Obrázek 1. V případě, že si respondent vybaví Prec, je pravděpodobnost vyvolání vyšší než počet slabik. Pravděpodobnost zapamatování pro slova s různým počtem slabik (modré body), rozdělení pravděpodobností zapamatování (černá) a střední hodnota pravděpodobnosti zapamatování (zelená) vypočtená z experimentálních dat. Korelační koeficient mezi počtem slabik a pravděpodobností zapamatování je 0,15, p < 10-6).
Tento výsledek zdánlivě odporuje klasickému efektu délky slova, kdy se ukázalo, že seznamy krátkých slov se zapamatovávají lépe než seznamy delších slov (Baddeley et al., 1975; Russo a Grammatopoulou, 2003; Tehan a Tolan, 2007; Bhatarah et al., 2009). Abychom otestovali, zda lze oba tyto efekty vysvětlit námi navrhovaným mechanismem vyhledávání, simulovali jsme model napodobující experimentální paradigmata ve dvou podmínkách – bez vybavování se seznamy složenými z krátkých/dlouhých slov a náhodnými seznamy (viz Metody). Ukázal se překvapivý výsledek: výkon v úloze volného vybavování závisí na experimentálním paradigmatu – při vybavování náhodné směsi nesouvisejících slov se statisticky snadněji vybavují delší slova, zatímco v seznamech složených ze slov s pevným počtem slabik se snadněji vybavují kratší slova (obrázek 2).
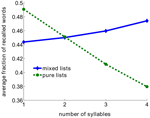
Obr. 2. Ukázalo se, že výkon v úloze volného vybavování závisí na experimentálním paradigmatu. Průměrný podíl vyvolaných slov v závislosti na počtu slabik v modelu. Čisté seznamy jsou sestaveny pouze ze slov se stejným počtem slabik. Smíšené seznamy jsou sestaveny z celého fondu slov.
Většina vysvětlení klasických efektů délky slov předpokládá, že celková délka prezentovaných podnětů negativně koreluje s počtem vyvolaných slov. Abychom ověřili, zda je toto tvrzení podpořeno daty, vypočítali jsme korelaci mezi počtem slabik v prezentovaných seznamech a počtem vyvolaných slov. Nezjistili jsme prakticky žádnou korelaci (korelační koeficient je 0,004 a významně se neliší od 0, p = 0,67).
Diskuse
Efekt délky slova, tj. zjištění, že seznamy krátkých slov se vybavují lépe než seznamy dlouhých slov (Baddeley et al., 1975), je považován za jeden z klíčových jevů v teoriích krátkodobé paměti (Campoy, 2011; Jalbert et al., 2011). Zde uvádíme, že při volném vybavování nesouvisejících slov, kdy jsou krátká a dlouhá slova náhodně smíchána, mají dlouhá slova vyšší pravděpodobnost zapamatování než krátká, což je ve zdánlivém rozporu s efektem délky slova.
Klasický efekt délky slova se tradičně vysvětluje buď zvýšenou složitostí delších položek (Neath a Nairne, 1995), nebo prodlouženou dobou nácviku delších položek (Baddeley, 1986, 2003; Page a Norris, 1998; Burgess a Hitch, 1999). První možnost předpokládá, že kratší slova jsou obecně snazší na zapamatování, což není v souladu s naším pozorováním. V druhém případě lze díky kratšímu času zkoušení nacvičit více krátkých slov, a proto se jich vybaví více. Toto vysvětlení nespecifikuje, v jakém pořadí by si člověk prezentovaná slova nacvičoval, ale naznačuje negativní korelaci mezi celkovou délkou prezentovaných položek a počtem vyvolaných slov, zatímco v datech žádná taková korelace neexistuje.
Ukazujeme zde, že námi nedávno navržený mechanismus asociativního vyhledávání může potenciálně vysvětlit jak klasický efekt délky slov (který je přítomen i v experimentech s volným vyvoláváním, viz Russo a Grammatopoulou, 2003; Bhatarah et al., 2009), tak opačný efekt délky v seznamech náhodně vybraných slov uvedený v tomto příspěvku. Na rozdíl od stávajících modelů hraje v našem modelu rozhodující roli dlouhodobá neuronální reprezentace položek a není vyžadován žádný samostatný mechanismus krátkodobé paměti. Zejména pravděpodobnost vyvolání položek v náhodných seznamech roste s velikostí jejich reprezentace ve srovnání s velikostí ostatních položek a tyto položky jsou vyvolány dříve a potlačují položky s menší reprezentací (Romani et al., 2013). Průměrná pravděpodobnost vyvolání celého souboru položek však nezávisí na průměrné velikosti reprezentace, ale negativně souvisí s rozptylem velikosti reprezentace v celém souboru (Katkov et al., submitted). Předpokládali jsme proto, že delší slova nemají v průměru větší zastoupení než slova kratší, ale mají společně vyšší rozptyl velikosti zastoupení. Tento předpoklad nemá v současnosti žádné přímé biologické opodstatnění, ale umožnil nám sladit zdánlivý rozpor mezi experimentálními pozorováními. Zejména vysvětluje klasický efekt délky slova, kdy jsou prezentována pouze slova s danou délkou slabiky, a proto se rozptyl velikosti reprezentace zvyšuje s délkou slabiky. V seznamech se smíšenou slabičnou délkou mají v některých pokusech největší neuronální reprezentaci položky s delší slabičnou délkou. Při prezentaci těchto seznamů mají delší slova větší pravděpodobnost, že se vybaví, a potlačují tak vybavování ostatních položek, což vede k mírné pozitivní korelaci mezi slabičnou délkou položky a pravděpodobností jejího vybavování.
Výsledky prezentované v tomto příspěvku ukazují, že délka slova je významným faktorem, který ovlivňuje snadnost jeho vybavování. Poznamenáváme však, že pravděpodobnost zapamatování stále vykazuje široké rozdělení i pro slova dané délky, což naznačuje, že k pravděpodobnosti zapamatování slova přispívají i další, dosud neznámé vlastnosti slova.
Prohlášení o střetu zájmů
Autoři prohlašují, že výzkum byl prováděn bez jakýchkoli komerčních nebo finančních vztahů, které by mohly být chápány jako potenciální střet zájmů.
Poděkování
Jsme vděčni M. Kahanovi za velkorysé poskytnutí dat získaných v jeho laboratoři. Laboratoř M. Kahany je podporována grantem NIH MH55687. Misha Tsodyks je podporován 7. rámcovým programem EU (grantová dohoda 604102), Izraelskou vědeckou nadací a nadací Adelis. Sandro Romani je podporován dlouhodobým stipendiem Human Frontier Science Program.
Baddeley, A. D. (1986). Working Memory (Pracovní paměť). Oxford, Anglie: Oxford University Press.
Baddeley, A. D. (2003). Pracovní paměť a jazyk: přehled. J. Commun. Disord. 36, 189-208. doi: 10.1016/s0021-9924(03)00019-4
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Baddeley, A. D., Thomson, N., and Buchanan, M. (1975). Délka slov a struktura krátkodobé paměti. J. Verbal Learn. Verbal Behav. 14, 575-589. doi: 10.1016/s0022-5371(75)80045-4
CrossRef Full Text | Google Scholar
Bhatarah, P., Ward, G., Smith, J., and Hayes, L. (2009). Zkoumání vztahu mezi volným zapamatováním a okamžitým sériovým zapamatováním: podobné vzorce nácviku a podobné účinky délky slov, rychlosti prezentace a artikulačního potlačení. Mem. Cognit. 37, 689-713. doi: 10.3758/MC.37.5.689
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Burgess, N., and Hitch, G. (1999). Paměť pro sériové pořadí: síťový model fonologické smyčky a jejího načasování. Psychol. Rev. 106, 551-581. doi: 10.1037//0033-295x.106.3.551
CrossRef Full Text | Google Scholar
Campoy, G. (2011). Retroaktivní interference v krátkodobé paměti a efekt délky slova. Acta Psychol. (Amst) 138, 135-142. doi: 10.1016/j.actpsy.2011.05.016
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Hulme, C., Suprenant, A. M., Bireta, T. J., Stuart, G., and Neath, I. (2004). Zrušení efektu délky slova. J. Exp. Psychol. Learn. Mem. Cogn. 30, 98-106. doi: 10.1037/0278-7393.30.1.98
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Jalbert, A., Neath, I., Bireta, T. J., and Surprenant, A. M. (2011). Kdy délka způsobuje efekt délky slova. J. Exp. Psychol. Learn. Mem. Cogn. 37, 338-353. doi: 10.1037/a0021804
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Miller, J. F., Kahana, M. J., and Weidemann, C. T. (2012). Ukončování vzpomínek při volné vzpomínce. Mem. Cogn. 40, 540-550. doi: 10.3758/s13421-011-0178-9
CrossRef Full Text | Google Scholar
Neath, I., and Nairne, J. S. (1995). Efekty délky slova v bezprostřední paměti: teorie přepisování rozpadu stop. Psychon. Bull. Rev. 2, 429-441. doi: 10.3758/bf03210981
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Page, M. P. A., and Norris, D. (1998). The primacy model: a new model of immediate serial recall (Model prvenství: nový model bezprostředního sériového vybavování). Psychol. Rev. 105, 761-781. doi: 10.1037//0033-295x.105.4.761-781
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Romani, S., Pinkoviezky, I., Rubin, A., and Tsodyks, M. (2013). Zákony škálování při vyhledávání v asociativní paměti. Neural Comput. 25, 2523-2544. doi: 10.1162/NECO_a_00499
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Russo, R., and Grammatopoulou, N. (2003). Délka slova a artikulační potlačení ovlivňují úlohy krátkodobého a dlouhodobého zapamatování. Mem. Cognit. 31, 728-737. doi: 10.3758/bf03196111
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Tehan, G., and Tolan, G. A. (2007). Efekt délky slova v dlouhodobé paměti. J. Mem. Lang. 56, 35-48. doi: 10.1016/j.jml.2006.08.015
CrossRef Full Text | Google Scholar
.