Frontiers in Computational Neuroscience
Introducere
Recent am propus un mecanism de recuperare asociativă a informațiilor care ia în considerare în mod explicit reprezentările neuronale pe termen lung ale elementelor de memorie (Romani et al., 2013). Una dintre predicțiile de bază ale modelului este existența unor cuvinte „ușoare” și „dificile”. Această predicție a fost verificată în analiza noastră a unui set mare de date de experimente de reamintire liberă colectate în laboratorul lui Michael Kahana, unde am arătat că probabilitatea de reamintire a cuvintelor sunt consecvente între grupuri de subiecți aleși în mod arbitrar (Katkov et al., prezentat). Întrebarea firească pusă de aceste observații este ce caracteristici sunt predictive pentru dificultatea cuvintelor în experimentele de reamintire, în special care este contribuția, dacă este cazul, a lungimii cuvintelor.
Majoritatea studiilor anterioare privind efectul lungimii cuvintelor au folosit liste care erau compuse în mod specific fie din cuvinte scurte, fie din cuvinte lungi. În două studii anterioare în care au fost utilizate liste compuse alternativ din cuvinte scurte și lungi, nu a fost observat niciun efect al lungimii cuvintelor (Hulme et al., 2004; Jalbert et al., 2011). Contribuția noastră actuală utilizează paradigma de reamintire liberă și se bazează pe un set de date mult mai mare decât studiile anterioare. Raportăm că, atunci când cuvintele sunt selectate aleatoriu, indiferent de lungimea lor, cuvintele lungi sunt reamintite mai bine decât cele scurte, într-o aparentă contradicție cu efectul clasic al lungimii cuvintelor atât în memoria serială, cât și în memoria liberă (Baddeley et al., 1975; Russo și Grammatopoulou, 2003; Tehan și Tolan, 2007; Bhatarah et al., 2009). Oferim o posibilă rezolvare a acestei contradicții în cadrul modelului de recuperare asociativă din (Romani et al., 2013).
Materiale și metode
Metode experimentale
Datele raportate în acest manuscris au fost colectate în laboratorul lui M. Kahana ca parte a studiului Penn Electrophysiology of Encoding and Retrieval Study (vezi Miller et al., 2012 pentru detalii despre experimente). Aici am analizat rezultatele de la 141 de participanți (vârsta 17-30) care au finalizat prima fază a experimentului, constând în șapte sesiuni experimentale. Participanții au fost consimțiți în conformitate cu protocolul IRB al Universității din Pennsylvania și au fost recompensați pentru participarea lor. Fiecare sesiune a constat în 16 liste de 16 cuvinte prezentate pe rând pe un ecran de calculator și a durat aproximativ 1,5 h. Fiecare listă de studiu a fost urmată de un test de reamintire liberă imediată. Cuvintele au fost extrase dintr-un grup de 1638 de cuvinte. Pentru fiecare listă, a existat o întârziere de 1500 ms înainte ca primul cuvânt să apară pe ecran. Fiecare element a fost pe ecran timp de 3000 ms, urmat de un interval inter-stimul de 800-1200 ms jittered (distribuție uniformă). După ultimul element din listă, a existat o întârziere jittered de 1200-1400 ms, după care participantul a avut la dispoziție 75 s pentru a încerca să își amintească oricare dintre elementele care tocmai fuseseră prezentate. Au fost utilizate toate încercările; intruziunile și repetițiile au fost eliminate din încercări.
Modelul
Supunem că fiecare cuvânt este reprezentat de o populație aleasă aleatoriu de neuroni în rețeaua de memorie dedicată. Presupunem, de asemenea, că fiecare element recuperat acționează ca un indiciu intern pentru următorul în funcție de măsura de similaritate dintre elemente, care este definită ca o mărimea intersecției dintre populațiile corespunzătoare (numărul de neuroni care reprezintă ambele elemente). Urmând (Romani et al., 2013), luăm în considerare procesul de recuperare care este determinat direct de reprezentările de memorie ale itemilor, fără a simula în mod explicit activitatea rețelei. Dinamica recuperării este descrisă de o secvență de itemi rechemați. Primul este ales în mod aleatoriu dintre cele prezentate, iar fiecare element rechemat ulterior este ales pentru a fi cel care are o similitudine maximă cu cel rechemat în prezent, fără a lua în considerare doar elementul „vizitat” (Romani et al., 2013). Rechemarea se termină atunci când procesul de recuperare intră într-un ciclu și nu mai pot fi recuperați alți itemi.
Pentru a imita protocolul experimental (a se vedea mai sus), am generat W = 1638 de modele binare aleatoare de lungime N: {ξiw = 0; 1} cu w = 1, … , W; i = 1, … , N indică neuronii din rețea, astfel încât ξiw = 1 dacă neuronii i participă la codificarea elementului de memorie w. Similaritatea dintre elementele w și w′ este apoi calculată ca Swww′=∑i=1Nξiwξiξiw′. Componentele modelului pentru fiecare element au fost extrase independent, cu probabilitatea pw de ξiw = 1 aleasă în felul următor: fiecărui model i s-a atribuit în mod arbitrar o lungime silabică lw = 1…4, astfel încât distribuția lui lw între modele să corespundă distribuției corespunzătoare între cuvintele utilizate în experiment (cinci cuvinte cu o lungime silabică mai mare de patru au fost combinate cu cele de lungime patru). Pentru modelele cu lw dată, pw corespunzătoare au fost distribuite în mod echidistant de la 0,02 – 10-3lw la 0,02 + 10-3lw. Cu această alegere a statisticilor modelelor, numărul mediu de neuroni care reprezintă un anumit element nu depinde de lungimea sa silabică, în timp ce varianța crește odată cu lungimea silabică. Reprezentările cuvintelor au fost apoi fixate pe tot parcursul experimentului simulat.
Pentru fiecare încercare simulată de reamintire, L = 16 itemi au fost aleși pentru prezentare în conformitate cu două protocoale experimentale. Pentru primul, itemii au fost selectați în mod complet independent, ca în experimentul lui Kahana. Pentru cel de-al doilea protocol, itemii cu același lw au fost selectați în mod aleatoriu. Procesul de reamintire a fost simulat ca în (Romani et al., 2013). Primul item rechemat a fost ales aleatoriu dintre cei prezentați. Tranzițiile ulterioare între itemii rechemați au fost determinate de matricea de similaritate S dintre ei, fiecare element al căreia a fost calculat ca număr de neuroni din intersecția dintre reprezentările corespunzătoare: Sww′=∑i=1Nξiwξiw′. Mai exact, următorul element recuperat este cel care are similitudinea maximă cu cel recuperat în prezent, cu excepția elementului care a fost recuperat chiar înainte de cel curent. Rechemarea se termină atunci când procesul de recuperare intră într-un ciclu și nu mai pot fi recuperați alți itemi.
Rezultate
Am analizat un set mare de date de experimente de recuperare liberă efectuate de 141 de subiecți cu 112 încercări per subiect. Datele sunt colectate în laboratorul lui Michael Kahana. Listele au fost compuse din 16 cuvinte selectate aleatoriu dintr-un grup de 1638 de cuvinte. Au fost utilizate toate încercările; intruziunile și repetițiile au fost eliminate din încercări (în total 15792 încercări, a se vedea secțiunea Metode). Pentru fiecare cuvânt, probabilitatea globală de reamintire (Prec) a fost calculată ca fracțiune de încercări în care acest cuvânt a fost reamintit atunci când a fost prezentat. Figura 1 prezintă distribuția lui (Prec) pentru toate cuvintele care au numărul dat de silabe (negru) agregate din toate încercările. Distribuția lui Prec este largă pentru toate lungimile de cuvânt. Cu toate acestea, probabilitatea medie de reamintire și varianța acesteia cresc monoton cu numărul de silabe (coeficientul de corelație este 0,15, p < 10-6).
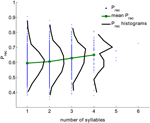
Figura 1. Probabilitatea de rechemare pentru cuvinte cu număr diferit de silabe (puncte albastre), distribuția probabilităților de rechemare (negru) și valoarea medie a probabilității de rechemare (verde) calculată din datele experimentale. Coeficientul de corelație dintre numărul de silabe și probabilitatea de reamintire este 0,15, p < 10-6).
Acest rezultat contrazice aparent efectul clasic al lungimii cuvintelor, în care s-a demonstrat că listele de cuvinte scurte sunt reamintite mai bine decât listele de cuvinte mai lungi (Baddeley et al., 1975; Russo și Grammatopoulou, 2003; Tehan și Tolan, 2007; Bhatarah et al., 2009). Pentru a testa dacă aceste două efecte pot fi explicate de mecanismul de recuperare propus de noi, am simulat modelul imitând paradigme experimentale în două condiții – reamintire fără condiții cu liste compuse din cuvinte scurte / lungi și liste aleatorii (a se vedea Metode). A reieșit un rezultat surprinzător: performanța în sarcina de reamintire liberă depinde de paradigma experimentală – în cazul reamintirii unui amestec aleatoriu de cuvinte fără legătură între ele, cuvintele mai lungi sunt mai ușor de reamintit din punct de vedere statistic, în timp ce în listele compuse din cuvinte cu număr fix de silabe, cuvintele mai scurte sunt mai ușor de reamintit (Figura 2).
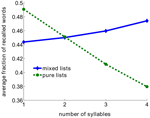
Figura 2. Fracția medie de cuvinte rechemate în funcție de numărul de silabe din model. Listele pure sunt compuse folosind numai cuvinte cu același număr de silabe. Listele mixte sunt compuse din întregul grup de cuvinte.
Majoritatea explicațiilor efectelor clasice ale lungimii cuvintelor presupun că lungimea totală a stimulilor prezentați este corelată negativ cu numărul de cuvinte reamintite. Pentru a testa dacă această afirmație este susținută de date, am calculat corelația dintre numărul de silabe din listele prezentate și numărul de cuvinte rechemate. Nu am găsit practic nicio corelație (coeficientul de corelație este de 0,004 și nu este semnificativ diferit de 0, p = 0,67).
Discuție
Efectul de lungime a cuvintelor, adică observația că listele de cuvinte scurte sunt reamintite mai bine decât listele de cuvinte lungi (Baddeley et al., 1975) este considerat a fi unul dintre fenomenele cheie în teoriile memoriei pe termen scurt (Campoy, 2011; Jalbert et al., 2011). Aici raportăm că în reamintirea liberă a cuvintelor fără legătură, unde cuvintele scurte și lungi sunt amestecate la întâmplare, cuvintele lungi au o probabilitate de reamintire mai mare decât cele scurte, în aparentă contradicție cu efectul lungimii cuvintelor.
Efectul clasic al lungimii cuvintelor este explicat în mod tradițional fie prin complexitatea crescută a itemilor mai lungi (Neath și Nairne, 1995), fie prin creșterea timpului de repetare a itemilor mai lungi (Baddeley, 1986, 2003; Page și Norris, 1998; Burgess și Hitch, 1999). Prima explicație sugerează că cuvintele mai scurte sunt, în general, mai ușor de reamintit, ceea ce nu este compatibil cu observația noastră. În cea de-a doua explicație, mai multe cuvinte scurte pot fi repetate, datorită timpului de repetare mai scurt, și, prin urmare, mai multe dintre ele sunt reamintite. Această explicație nu specifică în ce ordine s-ar repeta cuvintele prezentate, dar sugerează o corelație negativă între lungimea totală a elementelor prezentate și numărul de cuvinte rechemate, în timp ce nu există o astfel de corelație în date.
Aici arătăm că mecanismul nostru recent sugerat de recuperare asociativă poate explica potențial atât efectul clasic al lungimii cuvintelor (care este prezent și în experimentele de rechemare liberă, a se vedea Russo și Grammatopoulou, 2003; Bhatarah et al., 2009), cât și efectul opus al lungimii în listele de cuvinte selectate aleatoriu, raportat în această contribuție. Spre deosebire de modelele existente, reprezentarea neuronală pe termen lung a elementelor joacă un rol crucial în modelul nostru și nu este necesar un mecanism separat de memorie pe termen scurt. În special, probabilitatea de rechemare a elementelor din listele aleatorii crește odată cu dimensiunea reprezentării sale în raport cu cea a altor elemente, iar aceste elemente sunt rechemate mai devreme și suprimă elementele cu reprezentări mai mici (Romani et al., 2013). Probabilitatea medie de rechemare a întregului grup de itemi este însă independentă de dimensiunea medie a reprezentării, dar are o relație negativă cu varianța dimensiunii reprezentării în cadrul grupului (Katkov et al., prezentat). Prin urmare, am presupus că, în medie, cuvintele mai lungi nu au o reprezentare mai mare decât cele mai scurte, ci au în mod colectiv o varianță mai mare a mărimii reprezentării. Această ipoteză nu are în prezent o justificare biologică directă, dar ne-a permis să reconciliem contradicția aparentă dintre observațiile experimentale. În special, ea explică efectul clasic al lungimii cuvintelor, în care sunt prezentate numai cuvinte cu o anumită lungime silabică și, prin urmare, varianța mărimii reprezentării crește odată cu lungimea silabică. În listele cu lungime silabică mixtă, în unele încercări, elementele cu lungime silabică mai mare au cea mai mare reprezentare neuronală. Atunci când sunt prezentate aceste liste, cuvintele mai lungi au o probabilitate mai mare de a fi reamintite, suprimând alte elemente de a fi reamintite, rezultând o corelație pozitivă ușoară între lungimea silabică a unui element și probabilitatea de reamintire a acestuia.
Rezultatele prezentate în această contribuție arată că lungimea cuvântului este un factor proeminent care afectează ușurința cu care acesta este reamintit. Cu toate acestea, observăm că probabilitățile de reamintire prezintă în continuare o distribuție largă chiar și pentru cuvinte de o anumită lungime, ceea ce indică faptul că și alte caracteristici ale cuvântului, încă necunoscute, contribuie la probabilitatea de reamintire a unui cuvânt.
Declarație privind conflictul de interese
Autorii declară că cercetarea a fost efectuată în absența oricăror relații comerciale sau financiare care ar putea fi interpretate ca un potențial conflict de interese.
Recunoștințe
Suntem recunoscători lui M. Kahana pentru că ne-a împărtășit cu generozitate datele obținute în laboratorul său. Laboratorul lui Kahana este susținut de grantul NIH MH55687. Misha Tsodyks este susținut de FP7 al UE (acordul de grant 604102), de Fundația israeliană pentru știință și de Fundația Adelis. Sandro Romani este susținut de o bursă pe termen lung din partea Human Frontier Science Program.
Baddeley, A. D. (1986). Memoria de lucru. Oxford, Anglia: Oxford University Press.
Baddeley, A. D. (2003). Memoria de lucru și limbajul: o privire de ansamblu. J. Commun. Disord. 36, 189-208. doi: 10.1016/s0021-9924(03)00019-4
Pubmed Abstract | Pubmed Full Text | Pubmed Full Cross | Refef Full Text | Google Scholar
Baddeley, A. D., Thomson, N., și Buchanan, M. (1975). Lungimea cuvintelor și structura memoriei pe termen scurt. J. Verbal Learn. Verbal Behav. 14, 575-589. doi: 10.1016/s0022-5371(75)80045-4
CrossRef Full Text | Google Scholar
Bhatarah, P., Ward, G., Smith, J., and Hayes, L. (2009). Examinarea relației dintre reamintirea liberă și reamintirea serială imediată: modele similare de repetiție și efecte similare ale lungimii cuvântului, ratei de prezentare și suprimării articulatorii. Mem. Cognit. 37, 689-713. doi: 10.3758/MC.37.5.689
Pubmed Abstract | Pubmed Full Text | Pubmed Full Text | Google Scholar
Burgess, N., și Hitch, G. (1999). Memoria pentru ordinea serială: un model de rețea a buclei fonologice și a sincronizării sale. Psychol. Rev. 106, 551-581. doi: 10.1037//0033-295x.106.3.551
CrossRef Full Text | Google Scholar
Campoy, G. (2011). Interferența retroactivă în memoria pe termen scurt și efectul de lungime a cuvintelor. Acta Psychol. (Amst) 138, 135-142. doi: 10.1016/j.actpsy.2011.05.016
Pubmed Abstract | Pubmed Full Text | Pubmed Full Cross |Ref Full Text | Google Scholar
Hulme, C., Suprenant, A. M., Bireta, T. J., Stuart, G., și Neath, I. (2004). Abolirea efectului de lungime a cuvintelor. J. Exp. Psychol. Learn. Mem. Cogn. 30, 98-106. doi: 10.1037/0278-7393.30.1.98
Pubmed Abstract | Pubmed Full Text | Pubmed Full Cross |Ref Full Text | Google Scholar
Jalbert, A., Neath, I., Bireta, T. J., și Surprenant, A. M. (2011). Când provoacă lungimea efectul de lungime a cuvântului?”. J. Exp. Psychol. Learn. Mem. Cogn. 37, 338-353. doi: 10.1037/a0021804
Pubmed Abstract | Pubmed Full Text | Refef Full Text | Google Scholar
Miller, J. F., Kahana, M. J. J., și Weidemann, C. T. (2012). Terminarea rechemării în memoria liberă. Mem. Cogn. 40, 540-550. doi: 10.3758/s13421-011-0178-9
CrossRef Full Text | Google Scholar
Neath, I., și Nairne, J. S. (1995). Efectele de lungime a cuvintelor în memoria imediată: teoria descompunerii urmelor de suprascriere. Psychon. Bull. Rev. 2, 429-441. doi: 10.3758/bf03210981
Pubmed Abstract | Pubmed Full Text | Pubmed Full Text | Google Scholar
Page, M. P. A., și Norris, D. (1998). Modelul primatului: un nou model de reamintire serială imediată. Psychol. Rev. 105, 761-781. doi: 10.1037//0033-295x.105.4.761-781
Pubmed Abstract | Pubmed Full Text | Pubmed Full Text | Google Scholar
Romani, S., Pinkoviezky, I., Rubin, A., și Tsodyks, M. (2013). Legile de scalare ale recuperării memoriei asociative. Neural Comput. 25, 2523-2544. doi: 10.1162/NECO_a_00499
Pubmed Abstract | Pubmed Full Text | Pubmed Full Text | CrossRef Full Text | Google Scholar
Russo, R., and Grammatopoulou, N. (2003). Lungimea cuvintelor și suprimarea articulatorie afectează sarcinile de reamintire pe termen scurt și pe termen lung. Mem. cognit. 31, 728-737. doi: 10.3758/bf03196111
Pubmed Abstract | Pubmed Full Text | Pubmed Full Cross |Ref Full Text | Google Scholar
Tehan, G., and Tolan, G. A. (2007). Efectele lungimii cuvintelor în memoria pe termen lung. J. Mem. Lang. 56, 35-48. doi: 10.1016/j.jml.2006.08.015
CrossRef Full Text | Google Scholar
.