Frontiers in Computational Neuroscience
Introduction
Recentemente propusemos um mecanismo de recuperação de informação associativa que leva explicitamente em conta as representações neuronais de longo prazo dos itens de memória (Romani et al., 2013). Uma das previsões básicas do modelo é a existência de palavras “fáceis” e “difíceis”. Esta previsão foi verificada em nossa análise de um grande conjunto de dados de experimentos de memória livre coletados no laboratório de Michael Kahana, onde mostramos que a probabilidade das palavras a serem lembradas são consistentes entre grupos de sujeitos escolhidos arbitrariamente (Katkov et al., submetidos). A questão natural colocada por estas observações é que características são preditivas para a dificuldade da palavra em relembrar os experimentos, em particular, se alguma é a contribuição do comprimento da palavra.
A maior parte dos estudos anteriores de efeito de comprimento de palavra utilizou listas que eram compostas especificamente de palavras curtas ou longas. Em dois estudos anteriores em que foram utilizadas listas compostas alternadamente de palavras curtas e longas, não foi observado qualquer efeito de comprimento de palavra (Hulme et al., 2004; Jalbert et al., 2011). Nossa contribuição atual usa um paradigma de lembrança livre e é baseada em um conjunto de dados muito maior do que os estudos anteriores. Relatamos que quando as palavras são seleccionadas aleatoriamente, independentemente do seu comprimento, as palavras longas são recordadas melhor do que as curtas, numa aparente contradição com o efeito clássico de comprimento de palavra, tanto na recordação em série como na recordação livre (Baddeley et al., 1975; Russo e Grammatopoulou, 2003; Teerão e Tolan, 2007; Bhatarah et al., 2009). Nós fornecemos uma possível resolução desta contradição no quadro do modelo de recuperação associativa de (Romani et al., 2013).
Materiais e Métodos
Métodos Perimentais
Os dados relatados neste manuscrito foram coletados no laboratório de M. Kahana como parte do Penn Electrophysiology of Encoding and Retrieval Study (ver Miller et al., 2012 para detalhes dos experimentos). Aqui foram analisados os resultados dos 141 participantes (idade 17-30 anos) que completaram a primeira fase do experimento, que consistiu em sete sessões experimentais. Os participantes foram autorizados de acordo com o protocolo IRB da Universidade da Pensilvânia e foram compensados pela sua participação. Cada sessão consistiu de 16 listas de 16 palavras apresentadas uma de cada vez na tela do computador e durou aproximadamente 1,5 h. Cada lista de estudo foi seguida por um teste de recall gratuito imediato. As palavras foram extraídas de um conjunto de 1638 palavras. Para cada lista, houve um atraso de 1500 ms antes de a primeira palavra aparecer na tela. Cada item estava na tela por 3000 ms, seguido por um intervalo de 800-1200 ms entre estímulos (distribuição uniforme). Após o último item da lista, houve um atraso de 1200-1400 ms, após o qual o participante recebeu 75 s para tentar lembrar qualquer um dos itens recém apresentados. Todas as tentativas foram usadas; intrusões e repetições foram removidas das tentativas.
O Modelo
Apesamos que cada palavra é representada por uma população de neurônios escolhidos aleatoriamente na rede de memória dedicada. Assumimos ainda que cada item recuperado atua como taco interno para o próximo de acordo com a medida de similaridade entre os itens, que é definida como o tamanho da intersecção entre as populações correspondentes (o número de neurônios que representam ambos os itens). A seguir (Romani et al., 2013), consideramos o processo de recuperação que é determinado diretamente pelas representações de memória dos itens, sem simular explicitamente a atividade da rede. A dinâmica da recuperação é descrita por uma sequência de itens recuperados. O primeiro é escolhido aleatoriamente entre os apresentados, e cada item lembrado posteriormente é escolhido para ser aquele que tem uma semelhança máxima com o atualmente lembrado, sem contar apenas o item “visitado” (Romani et al., 2013). O recall é encerrado quando o processo de recuperação entra em um ciclo e nenhum outro item pode ser recuperado.
Para imitar o protocolo experimental (veja acima), geramos W = 1638 padrões binários aleatórios de comprimento N: {ξiw = 0; 1} com w = 1, … , W; i = 1, … , N indica os neurônios na rede, de tal forma que ξiw = 1 se o neurônio i estiver participando da codificação do item de memória w. A semelhança entre os itens w e w′ é então calculada como Sww′=∑i=1Nξiwξiw′. Os componentes do padrão para cada item foram desenhados independentemente com a probabilidade pw de ξiw = 1 escolhida da seguinte forma: a cada padrão foi arbitrariamente atribuído um comprimento silábico lw = 1…4 de tal forma que a distribuição de lw através dos padrões correspondia à distribuição correspondente através das palavras usadas no experimento (cinco palavras com comprimento silábico maior que quatro foram combinadas com as de comprimento quatro). Para padrões com determinado lw, os pw correspondentes foram distribuídos equidistantemente de 0,02 – 10-3lw a 0,02 + 10-3lw. Com esta escolha de padrões estatísticos, o número médio de neurônios representando um determinado item não depende do seu comprimento silábico, enquanto que a variância está aumentando com o comprimento silábico. A palavra representações foram então fixadas ao longo do experimento simulado.
Para cada ensaio de recall simulado, L = 16 itens foram escolhidos para apresentação de acordo com dois protocolos experimentais. Para o primeiro, os itens foram selecionados de forma completamente independente, como no experimento de Kahana. Para o segundo protocolo, os itens com o mesmo lw foram selecionados aleatoriamente. O processo de retirada foi simulado como em (Romani et al., 2013). O primeiro item lembrado foi escolhido aleatoriamente entre os apresentados. As transições subsequentes entre os itens lembrados foram determinadas pela matriz de similaridade S entre eles, cada elemento foi computado como o número de neurônios na intersecção entre as representações correspondentes: Sww′=∑i=1Nξiwξiw′. Mais especificamente, o próximo item recuperado é aquele que tem a máxima semelhança com o atualmente recuperado, excluindo o item que foi recuperado pouco antes do atual. A recuperação é terminada quando o processo de recuperação entra em um ciclo e nenhum item mais pode ser recuperado.
Resultados
Analisamos um grande conjunto de dados de experimentos de recuperação livre realizados por 141 sujeitos com 112 tentativas por sujeito. Os dados são coletados no laboratório de Michael Kahana. As listas foram compostas de 16 palavras selecionadas aleatoriamente a partir de um conjunto de 1638 palavras. Todos os ensaios foram utilizados; intrusões e repetições foram removidas dos ensaios (no total 15792 ensaios, ver secção Métodos). Para cada palavra, foi calculada a sua probabilidade geral de recordação (Prec) como a fração de ensaios que esta palavra foi recordada quando foi apresentada. A Figura 1 mostra a distribuição de (Prec) para todas as palavras com o número dado de sílabas (pretas) agregadas de todos os ensaios. A distribuição do Prec é ampla para todos os comprimentos de palavras. No entanto, a probabilidade média de recuperação e sua variância cresce monotonicamente com o número de sílabas (coeficiente de correlação é 0,15, p < 10-6).
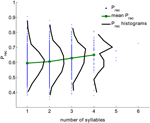
Figura 1. Probabilidade de recordação para palavras com diferentes números de sílabas (pontos azuis), a distribuição das probabilidades de recordação (preto) e o valor médio da probabilidade de recordação (verde) calculado a partir dos dados experimentais. O coeficiente de correlação entre o número de sílabas e a probabilidade de memória é 0,15, p < 10-6).
Este resultado parece contradizer o efeito clássico do comprimento das palavras, onde listas de palavras curtas foram mostradas como sendo melhores do que listas de palavras longas (Baddeley et al., 1975; Russo e Grammatopoulou, 2003; Tean e Tolan, 2007; Bhatarah et al., 2009). Para testar se esses dois efeitos podem ser explicados pelo nosso mecanismo de recuperação proposto, simulamos o modelo imitando paradigmas experimentais em duas condições de recall livre com listas compostas de palavras curtas/longas e listas aleatórias (ver Métodos). O resultado surpreendente surgiu: o desempenho na tarefa de recuperação livre depende do paradigma experimental – na recuperação da mistura aleatória de palavras não relacionadas palavras mais longas são estatisticamente mais fáceis de recuperar, enquanto que em listas compostas de palavras com o número fixo de sílabas, palavras mais curtas são mais fáceis de recuperar (Figura 2).
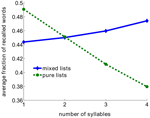
Figura 2. Fração média de palavras recuperadas em função do número de sílabas no modelo. Listas puras são compostas usando apenas palavras com o mesmo número de sílabas. Listas mistas são compostas a partir de todo o conjunto de palavras.
A maior parte das explicações dos efeitos clássicos do comprimento das palavras assume que o comprimento total dos estímulos apresentados está negativamente correlacionado com o número de palavras lembradas. Para testar se esta afirmação é suportada pelos dados, calculamos a correlação entre o número de sílabas nas listas apresentadas e o número de palavras lembradas. Praticamente não encontramos correlação (o coeficiente de correlação é 0,004 e não é significativamente diferente de 0, p = 0,67).
Discussão
Efeito de comprimento de palavra, ou seja, a observação de que listas de palavras curtas são melhor recordadas do que listas de palavras longas (Baddeley et al., 1975) é considerada um dos fenômenos-chave nas teorias da memória de curto prazo (Campoy, 2011; Jalbert et al., 2011). Aqui relatamos que na lembrança livre de palavras não relacionadas, onde palavras curtas e longas são misturadas aleatoriamente, as palavras longas têm maior probabilidade de lembrar do que as curtas, em aparente contradição com o efeito comprimento da palavra.
O clássico efeito comprimento da palavra é tradicionalmente explicado ou pelo aumento da complexidade dos itens mais longos (Neath e Nairne, 1995), ou pelo aumento do tempo de ensaio dos itens mais longos (Baddeley, 1986, 2003; Page e Norris, 1998; Burgess e Hitch, 1999). O primeiro relato sugere que palavras mais curtas são genericamente mais fáceis de lembrar, o que não é compatível com a nossa observação. No segundo relato, mais palavras curtas podem ser ensaiadas, devido ao menor tempo de ensaio, e, portanto, mais palavras são lembradas. Esta explicação não especifica em que ordem se ensaia as palavras apresentadas, mas sugere uma correlação negativa entre o comprimento total dos itens apresentados e o número de palavras lembradas, enquanto não existe tal correlação nos dados.
Aqui mostramos que nosso mecanismo de recuperação associativa recentemente sugerido pode potencialmente explicar tanto o efeito clássico do comprimento das palavras (que também está presente nos experimentos de recordação livre, ver Russo e Grammatopoulou, 2003; Bhatarah et al., 2009) quanto o efeito oposto do comprimento nas listas de palavras aleatoriamente selecionadas relatadas nesta contribuição. Em contraste com os modelos existentes, a representação neuronal de longo prazo dos itens desempenha um papel crucial em nosso modelo, e nenhum mecanismo separado de memória de curto prazo é necessário. Em particular, a probabilidade de lembrar itens em listas aleatórias está aumentando com o tamanho de sua representação em relação à de outros itens, e esses itens são lembrados mais cedo e suprimem os itens com representações menores (Romani et al., 2013). A probabilidade média de retirada de todo o conjunto de itens é, no entanto, independente do tamanho médio da representação, mas relaciona-se negativamente com a variação do tamanho da representação em todo o conjunto (Katkov et al., submetidos). Portanto, assumimos que palavras mais longas não têm, em média, uma representação maior do que as mais curtas, mas coletivamente têm uma variância maior do tamanho da representação. Essa suposição não tem atualmente nenhuma justificativa biológica direta, mas nos permitiu conciliar a aparente contradição entre as observações experimentais. Em particular, ela contabiliza o efeito clássico do comprimento da palavra, onde apenas palavras com um determinado comprimento de silábico são apresentadas, e portanto a variância do tamanho da representação aumenta com o comprimento do silábico. Em listas com comprimento sílabico misto, em alguns ensaios os itens com comprimento sílabico mais longo têm maior representação neuronal. Quando essas listas são apresentadas, palavras mais longas têm maior probabilidade de serem lembradas, suprimindo que outros itens sejam lembrados, resultando em leve correlação positiva entre o comprimento sílabico de um item e sua probabilidade de lembrança.
Os resultados apresentados nessa contribuição mostram que o comprimento da palavra é um fator proeminente que afeta a facilidade para que ela seja lembrada. No entanto, notamos que as probabilidades de lembrança ainda mostram uma ampla distribuição mesmo para palavras de determinado comprimento, indicando que outras, ainda desconhecidas, características da palavra também contribuem para a probabilidade de lembrança de uma palavra.
Conflict of Interest Statement
Os autores declaram que a pesquisa foi conduzida na ausência de quaisquer relações comerciais ou financeiras que pudessem ser interpretadas como um potencial conflito de interesses.
Acknowledgments
Estamos gratos a M. Kahana por generosamente compartilhar conosco os dados obtidos em seu laboratório. O laboratório de Kahana é apoiado pelo NIH grant MH55687. Misha Tsodyks é apoiado pela EU FP7 (Grant agreement 604102), Fundação Científica Israelita e Fundação Adelis. Sandro Romani é apoiado pelo Human Frontier Science Program (Programa de Bolsas de Estudo de Longo Prazo).
Baddeley, A. D. (1986). Memória de Trabalho. Oxford, Inglaterra: Oxford University Press.
Baddeley, A. D. (2003). Memória de trabalho e linguagem: uma visão geral. J. Commun. Disord. 36, 189-208. doi: 10.1016/s0021-9924(03)00019-4
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Baddeley, A. D., Thomson, N., e Buchanan, M. (1975). O comprimento da palavra e a estrutura da memória de curto prazo. J. Verbal Aprender. Comportamento Verbal. 14, 575-589. doi: 10.1016/s0022-5371(75)80045-4
CrossRef Full Text | Google Scholar
Bhatarah, P., Ward, G., Smith, J., and Hayes, L. (2009). Examinando a relação entre a chamada livre e a chamada em série imediata: padrões semelhantes de ensaio e efeitos semelhantes de comprimento de palavra, taxa de apresentação e supressão articulatória. Mem. Cognit. 37, 689-713. doi: 10.3758/MC.37.5.689
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Burgess, N., and Hitch, G. (1999). Memória para pedido em série: um modelo de rede do laço fonológico e seu tempo. Psicol. Rev. 106, 551-581. doi: 10.1037//0033-295x.106.3.551
CrossRef Full Text | Google Scholar
Campoy, G. (2011). Interferência retroativa na memória de curto prazo e o efeito de comprimento de palavra. Acta Psychol. (Amst) 138, 135-142. doi: 10.1016/j.actpsy.2011.05.016
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Hulme, C., Suprenant, A. M., Bireta, T. J., Stuart, G., and Neath, I. (2004). Abolindo o efeito de comprimento de palavra. J. Exp. Psychol. Learn. Mem. Cogn. 30, 98-106. doi: 10.1037/0278-7393.30.1.98
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Jalbert, A., Neath, I., Bireta, T. J., e Surprenant, A. M. (2011). Quando é que o comprimento causa o efeito da palavra comprimento? J. Exp. Psicol. Aprenda. Mem. Cogn. 37, 338-353. doi: 10.1037/a0021804
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Miller, J. F., Kahana, M. J., e Weidemann, C. T. (2012). Recall termination in free recall. Mem. Cogn. 40, 540-550. doi: 10.3758/s13421-011-0178-9
CrossRef Full Text | Google Scholar
Neath, I., e Nairne, J. S. (1995). Efeitos do comprimento de palavra na memória imediata: sobreposição da teoria da decomposição de traços. Psychon. Bull. Rev. 2, 429-441. doi: 10.3758/bf03210981
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Page, M. P. A., e Norris, D. (1998). O modelo da primazia: um novo modelo de chamada em série imediata. Psychol. Rev. 105, 761-781. doi: 10.1037//0033-295x.105.4.761-781
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Romani, S., Pinkoviezky, I., Rubin, A., e Tsodyks, M. (2013). Leis de escalonamento da recuperação da memória associativa. Neural Comput. 25, 2523-2544. doi: 10.1162/NECO_a_00499
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Russo, R., e Grammatopoulou, N. (2003). O comprimento de palavra e a supressão articulatória afetam as tarefas de recall a curto e longo prazo. Mem. Cognit. 31, 728-737. doi: 10.3758/bf03196111
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Tehan, G., and Tolan, G. A. (2007). Efeitos de comprimento de palavra na memória a longo prazo. J. Mem. Lang. 56, 35-48. doi: 10.1016/j.jml.2006.08.015
CrossRef Full Text | Google Scholar