Frontiers in Computational Neuroscience
Introduction
Onlangs hebben we een mechanisme van associatieve information retrieval voorgesteld dat expliciet rekening houdt met lange termijn neuronale representaties van geheugenitems (Romani et al., 2013). Een van de basisvoorspellingen van het model is het bestaan van “makkelijke” en “moeilijke” woorden. Deze voorspelling werd geverifieerd in onze analyse van een grote dataset van free recall experimenten verzameld in het lab van Michael Kahana, waar we aantoonden dat de waarschijnlijkheid van woorden die worden herinnerd consistent zijn tussen willekeurig gekozen groepen van proefpersonen (Katkov et al., submitted). De natuurlijke vraag die deze observaties oproepen is welke kenmerken voorspellend zijn voor de woordmoeilijkheid in recall experimenten, in het bijzonder wat de eventuele bijdrage is van de woordlengte.
De meeste van de eerdere studies naar het woordlengte effect gebruikten lijsten die specifiek waren samengesteld uit ofwel korte ofwel lange woorden. In twee eerdere studies waarin lijsten werden gebruikt die waren samengesteld uit afwisselend korte en lange woorden, werd geen woordlengte-effect waargenomen (Hulme et al., 2004; Jalbert et al., 2011). Onze huidige bijdrage maakt gebruik van het free recall paradigma en is gebaseerd op een veel grotere dataset dan eerdere studies. Wij rapporteren dat wanneer woorden willekeurig worden geselecteerd, ongeacht hun lengte, lange woorden beter worden herinnerd dan korte, in een schijnbare tegenspraak met het klassieke woordlengte-effect in zowel seriële als vrije recall (Baddeley et al., 1975; Russo and Grammatopoulou, 2003; Tehan and Tolan, 2007; Bhatarah et al., 2009). Wij bieden een mogelijke oplossing van deze tegenstelling in het kader van het associatieve retrieval model van (Romani et al., 2013).
Materialen en Methoden
Experimentele Methoden
De gegevens gerapporteerd in dit manuscript werden verzameld in het lab van M. Kahana als onderdeel van de Penn Electrophysiology of Encoding and Retrieval Study (zie Miller et al., 2012 voor details van de experimenten). Hier analyseren we de resultaten van de 141 deelnemers (leeftijd 17-30) die de eerste fase van het experiment hebben voltooid, bestaande uit zeven experimentele sessies. Deelnemers kregen toestemming volgens het IRB-protocol van de Universiteit van Pennsylvania en werden gecompenseerd voor hun deelname. Elke sessie bestond uit 16 lijsten van 16 woorden die één voor één werden gepresenteerd op een computerscherm en duurde ongeveer 1,5 uur. Woorden werden getrokken uit een pool van 1638 woorden. Voor elke lijst was er een vertraging van 1500 ms voordat het eerste woord op het scherm verscheen. Elk item was 3000 ms op het scherm, gevolgd door een inter-stimulus interval van 800-1200 ms (uniforme verdeling). Na het laatste item in de lijst volgde een vertraging van 1200-1400 ms, waarna de deelnemer 75 s de tijd kreeg om te proberen zich een van de zojuist gepresenteerde items te herinneren. Alle trials werden gebruikt; intrusies en herhalingen werden uit de trials verwijderd.
Het model
We nemen aan dat elk woord wordt gerepresenteerd door een willekeurig gekozen populatie van neuronen in het specifieke geheugennetwerk. We nemen verder aan dat elk opgehaald item fungeert als een interne cue voor het volgende volgens de mate van gelijkenis tussen de items, die wordt gedefinieerd als de grootte van de intersectie tussen de overeenkomstige populaties (het aantal neuronen dat beide items vertegenwoordigt). In navolging van (Romani et al., 2013) beschouwen we het terughaalproces dat direct wordt bepaald door geheugenrepresentaties van de items, zonder expliciete simulatie van netwerkactiviteit. De dynamiek van het terughalen wordt beschreven door een opeenvolging van teruggeroepen items. Het eerste item wordt willekeurig gekozen uit de gepresenteerde items, en elk volgend teruggeroepen item wordt gekozen om het item te zijn dat een maximale overeenkomst heeft met het huidige teruggeroepen item, het “bezochte” item niet meegerekend (Romani et al., 2013). De recall wordt beëindigd wanneer het recall proces een cyclus ingaat en er geen items meer kunnen worden opgehaald.
Om het experimentele protocol (zie boven) na te bootsen, genereerden we W = 1638 willekeurige binaire patronen van lengte N: {ξiw = 0; 1} met w = 1, … , W; i = 1, … , N geeft de neuronen in het netwerk aan, zodanig dat ξiw = 1 als neuron i deelneemt aan de codering van het geheugenitem w. De overeenkomst tussen items w en w′ wordt dan berekend als Sww′=∑i=1Nξiwξiw′. De patrooncomponenten voor elk item werden onafhankelijk getrokken met de waarschijnlijkheid pw van ξiw = 1 gekozen op de volgende manier: aan elk patroon werd willekeurig een syllabische lengte lw = 1…4 toegekend zodat de verdeling van lw over de patronen overeenkwam met de overeenkomstige verdeling over de woorden die in het experiment gebruikt werden (vijf woorden met een syllabische lengte groter dan vier werden gecombineerd met die van vier lengte). Voor patronen met een gegeven lw, waren de corresponderende pw gelijkmatig verdeeld van 0.02 – 10-3lw tot 0.02 + 10-3lw. Met deze keuze van patroonstatistieken hangt het gemiddelde aantal neuronen dat een bepaald item vertegenwoordigt niet af van de syllabische lengte, terwijl de variantie toeneemt met de syllabische lengte. De woordrepresentaties werden vervolgens gedurende het hele gesimuleerde experiment gefixeerd.
Voor elke gesimuleerde recall-trial werden L = 16 items gekozen voor presentatie volgens twee experimentele protocollen. Voor de eerste, items werden volledig onafhankelijk geselecteerd, zoals in het experiment van Kahana. Voor het tweede protocol werden items met hetzelfde lw willekeurig gekozen. Het terugroepproces werd gesimuleerd zoals in (Romani et al., 2013). Het eerste teruggeroepen item werd willekeurig gekozen uit de gepresenteerde items. Latere overgangen tussen teruggeroepen items werden bepaald door de gelijksoortigheidsmatrix S tussen hen, waarvan elk element werd berekend als het aantal neuronen in de intersectie tussen de corresponderende representaties: Sww′=∑i=1Nξiwξiw′. Meer specifiek, het volgende opgehaalde item is het item dat de maximale gelijkenis vertoont met het huidige opgehaalde item, met uitsluiting van het item dat net voor het huidige opgehaald werd. De recall wordt beëindigd wanneer het retrieval proces een cyclus ingaat en er geen items meer kunnen worden opgehaald.
Resultaten
We analyseerden een grote dataset van free recall experimenten uitgevoerd door 141 proefpersonen met 112 trials per proefpersoon. De gegevens zijn verzameld in het lab van Michael Kahana. De lijsten waren samengesteld uit 16 woorden willekeurig gekozen uit een pool van 1638 woorden. Alle trials werden gebruikt; intrusies en herhalingen werden uit de trials verwijderd (in totaal 15792 trials, zie Paragraaf Methoden). Voor elk woord werd de totale terugroepkans (Prec) berekend als de fractie van de trials waarin dit woord werd teruggeroepen wanneer het werd gepresenteerd. Figuur 1 toont de verdeling van (Prec) voor alle woorden met het gegeven aantal lettergrepen (zwart), geaggregeerd uit alle proeven. De verdeling van Prec is breed voor alle woordlengtes. Niettemin groeien de gemiddelde terugroepkans en de variantie monotoon met het aantal lettergrepen (correlatiecoëfficiënt is 0,15, p < 10-6).
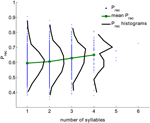
Figuur 1. Terugroepkansen voor woorden met verschillende aantallen lettergrepen (blauwe stippen), de verdeling van de terugroepkansen (zwart) en de gemiddelde waarde van de terugroepkansen (groen), berekend op basis van experimentele gegevens. Correlatiecoëfficiënt tussen het aantal lettergrepen en de terugroepkans is 0.15, p < 10-6).
Dit resultaat lijkt in tegenspraak met het klassieke woordlengte-effect, waarbij lijsten met korte woorden beter werden teruggeroepen dan lijsten met langere woorden (Baddeley et al., 1975; Russo and Grammatopoulou, 2003; Tehan and Tolan, 2007; Bhatarah et al., 2009). Om te testen of beide effecten verklaard kunnen worden door het door ons voorgestelde retrieval mechanisme, simuleerden we het model met het nabootsen van experimentele paradigma’s in twee condities-free recall met lijsten samengesteld uit korte/lange woorden en random lijsten (zie Methoden). Het verrassende resultaat kwam naar voren: de prestaties in de free-recall taak hangt af van het experimentele paradigma – in het terugroepen van een willekeurige mix van ongerelateerde woorden zijn langere woorden statistisch gezien makkelijker terug te roepen, terwijl in lijsten samengesteld uit woorden met een vast aantal lettergrepen, kortere woorden makkelijker terug te roepen zijn (figuur 2).
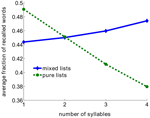
Figuur 2. Gemiddelde fractie van teruggeroepen woorden als functie van het aantal lettergrepen in het model. Zuivere lijsten zijn samengesteld met alleen woorden met hetzelfde aantal lettergrepen. Gemengde lijsten zijn samengesteld uit de hele pool van woorden.
De meeste verklaringen van klassieke woordlengte-effecten gaan ervan uit dat de totale lengte van gepresenteerde stimuli negatief gecorreleerd is met het aantal teruggeroepen woorden. Om te testen of deze verklaring wordt ondersteund door de data berekenden we de correlatie tussen het aantal lettergrepen in gepresenteerde lijsten en het aantal teruggeroepen woorden. We vonden vrijwel geen correlatie (correlatiecoëfficiënt is 0,004 en is niet significant verschillend van 0, p = 0,67).
Discussie
Het woordlengte-effect, d.w.z. de waarneming dat lijsten met korte woorden beter worden herinnerd dan lijsten met lange woorden (Baddeley et al., 1975), wordt beschouwd als een van de sleutelverschijnselen in de theorieën van het kortetermijngeheugen (Campoy, 2011; Jalbert et al., 2011). Hier rapporteren we dat in vrije recall van ongerelateerde woorden, waar korte en lange woorden willekeurig worden gemengd, lange woorden een hogere recall waarschijnlijkheid hebben dan korte, in schijnbare tegenspraak met het woordlengte-effect.
Het klassieke woordlengte-effect wordt traditioneel verklaard door ofwel toegenomen complexiteit van langere items (Neath en Nairne, 1995), of toegenomen repetitietijd van langere items (Baddeley, 1986, 2003; Page en Norris, 1998; Burgess en Hitch, 1999). De eerste verklaring suggereert dat kortere woorden in het algemeen gemakkelijker te onthouden zijn, wat niet strookt met onze waarneming. In de tweede verklaring kunnen meer korte woorden worden gerepeteerd, als gevolg van de kortere repetitietijd, en worden er dus meer van die woorden gerepeteerd. Deze verklaring specificeert niet in welke volgorde men gepresenteerde woorden zou repeteren, maar suggereert een negatieve correlatie tussen de totale lengte van gepresenteerde items en het aantal teruggeroepen woorden, terwijl een dergelijke correlatie niet bestaat in de data.
Hier laten we zien dat ons recent voorgestelde mechanisme van associatief terughalen mogelijk een verklaring kan bieden voor zowel het klassieke woordlengte-effect (dat ook aanwezig is in free recall experimenten, zie Russo en Grammatopoulou, 2003; Bhatarah et al., 2009) als het tegenovergestelde lengte-effect in lijsten van willekeurig gekozen woorden waarvan in deze bijdrage verslag wordt gedaan. In tegenstelling tot bestaande modellen speelt de lange-termijn neuronale representatie van items een cruciale rol in ons model, en is er geen apart korte-termijn geheugen mechanisme nodig. In het bijzonder neemt de recall waarschijnlijkheid van items in willekeurige lijsten toe met de grootte van zijn representatie ten opzichte van die van andere items, en deze items worden eerder teruggeroepen en onderdrukken de items met kleinere representaties (Romani et al., 2013). De gemiddelde recall-kans van de hele pool van items is echter onafhankelijk van de gemiddelde representatiegrootte, maar houdt negatief verband met de variantie van de representatiegrootte over de pool (Katkov et al., submitted). We veronderstelden daarom dat langere woorden gemiddeld geen grotere representatie hebben dan kortere, maar collectief een hogere variantie van representatiegrootte hebben. Deze aanname heeft op dit moment geen directe biologische rechtvaardiging, maar stelde ons in staat om de schijnbare tegenstrijdigheid tussen de experimentele observaties te verzoenen. In het bijzonder verklaart het het klassieke woordlengte-effect, waarbij alleen woorden met een bepaalde syllabische lengte worden gepresenteerd, en daarom de variantie van de representatiegrootte toeneemt met de syllabische lengte. In lijsten met een gemengde syllabische lengte hebben items met een langere syllabische lengte in sommige trials de grootste neuronale representatie. Wanneer deze lijsten worden gepresenteerd, hebben langere woorden een grotere kans om te worden herinnerd, waardoor andere items worden onderdrukt, wat resulteert in een milde positieve correlatie tussen de syllabische lengte van een item en zijn recall waarschijnlijkheid.
De resultaten in deze bijdrage tonen aan dat de lengte van het woord een prominente factor is die van invloed is op de gemakelijkheid waarmee het kan worden herinnerd. We merken echter op dat de terugroepkansen zelfs voor woorden van een bepaalde lengte nog steeds een grote spreiding vertonen, wat erop wijst dat andere, nog onbekende, woordkenmerken ook bijdragen aan de kans om een woord terug te roepen.
Conflict of Interest Statement
De auteurs verklaren dat het onderzoek is uitgevoerd in de afwezigheid van enige commerciële of financiële relaties die zouden kunnen worden opgevat als een potentieel belangenconflict.
Acknowledgments
We zijn M. Kahana dankbaar voor het genereus delen van de gegevens verkregen in zijn laboratorium met ons. Het lab van Kahana wordt ondersteund door NIH grant MH55687. Misha Tsodyks wordt gesteund door EU FP7 (Grant Agreement 604102), Israeli Science Foundation en Stichting Adelis. Sandro Romani wordt gesteund door Human Frontier Science Program long-term fellowship.
Baddeley, A. D. (1986). Werkgeheugen. Oxford, Engeland: Oxford University Press.
Baddeley, A. D. (2003). Werkgeheugen en taal: een overzicht. J. Commun. Disord. 36, 189-208. doi: 10.1016/s0021-9924(03)00019-4
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Baddeley, A. D., Thomson, N., and Buchanan, M. (1975). Word length and the structure of short-term memory. J. Verbal Learn. Verbal Behav. 14, 575-589. doi: 10.1016/s0022-5371(75)80045-4
CrossRef Full Text | Google Scholar
Bhatarah, P., Ward, G., Smith, J., and Hayes, L. (2009). Onderzoek naar de relatie tussen free recall en immediate serial recall: vergelijkbare patronen van repetitie en vergelijkbare effecten van woordlengte, presentatie snelheid en articulatorische onderdrukking. Mem. Cognit. 37, 689-713. doi: 10.3758/MC.37.5.689
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Burgess, N., and Hitch, G. (1999). Memory for serial order: a network model of the phonological loop and its timing. Psychol. Rev. 106, 551-581. doi: 10.1037//0033-295x.106.3.551
CrossRef Full Text | Google Scholar
Campoy, G. (2011). Retroactieve interferentie in het kortetermijngeheugen en het woord-lengte-effect. Acta Psychol. (Amst) 138, 135-142. doi: 10.1016/j.actpsy.2011.05.016
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Hulme, C., Suprenant, A. M., Bireta, T. J., Stuart, G., and Neath, I. (2004). Afschaffing van het woord-lengte effect. J. Exp. Psychol. Learn. Mem. Cogn. 30, 98-106. doi: 10.1037/0278-7393.30.1.98
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Jalbert, A., Neath, I., Bireta, T. J., and Surprenant, A. M. (2011). Wanneer veroorzaakt lengte het woordlengte-effect? J. Exp. Psychol. Learn. Mem. Cogn. 37, 338-353. doi: 10.1037/a0021804
Pubmed Abstract | Pubmed Full Text | Ref Full Text | Google Scholar
Miller, J. F., Kahana, M. J., and Weidemann, C. T. (2012). Recall termination in free recall. Mem. Cogn. 40, 540-550. doi: 10.3758/s13421-011-0178-9
CrossRef Full Text | Google Scholar
Neath, I., and Nairne, J. S. (1995). Word-length effects in immediate memory: overwriting trace decay theory. Psychon. Bull. Rev. 2, 429-441. doi: 10.3758/bf03210981
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Page, M. P. A., and Norris, D. (1998). The primacy model: a new model of immediate serial recall. Psychol. Rev. 105, 761-781. doi: 10.1037//0033-295x.105.4.761-781
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Romani, S., Pinkoviezky, I., Rubin, A., and Tsodyks, M. (2013). Schaling wetten van associatief geheugen ophalen. Neural Comput. 25, 2523-2544. doi: 10.1162/NECO_a_00499
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Russo, R., and Grammatopoulou, N. (2003). Word length and articulatory suppression affect short-term and long-term recall tasks. Mem. Cognit. 31, 728-737. doi: 10.3758/bf03196111
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Tehan, G., and Tolan, G. A. (2007). Woordlengte-effecten in het langetermijngeheugen. J. Mem. Lang. 56, 35-48. doi: 10.1016/j.jml.2006.08.015
CrossRef Full Text | Google Scholar