Frontiers in Computational Neuroscience
Introduction
Récemment, nous avons proposé un mécanisme de récupération d’information associative qui prend explicitement en compte les représentations neuronales à long terme des éléments de la mémoire (Romani et al., 2013). L’une des prédictions de base de ce modèle est l’existence de mots « faciles » et « difficiles ». Cette prédiction a été vérifiée dans notre analyse d’un grand ensemble de données d’expériences de rappel libre recueillies dans le laboratoire de Michael Kahana, où nous avons montré que la probabilité des mots à rappeler est cohérente entre des groupes de sujets choisis arbitrairement (Katkov et al., soumis). La question naturelle posée par ces observations est de savoir quelles caractéristiques sont prédictives de la difficulté des mots dans les expériences de rappel, en particulier quelle est la contribution éventuelle de la longueur des mots.
La plupart des études précédentes sur l’effet de la longueur des mots ont utilisé des listes qui étaient spécifiquement composées de mots courts ou longs. Dans deux études précédentes où des listes composées alternativement de mots courts et longs ont été utilisées, aucun effet de la longueur des mots n’a été observé (Hulme et al., 2004 ; Jalbert et al., 2011). Notre contribution actuelle utilise le paradigme du rappel libre et se base sur un ensemble de données beaucoup plus important que les études précédentes. Nous rapportons que lorsque les mots sont choisis au hasard, indépendamment de leur longueur, les mots longs sont mieux rappelés que les mots courts, ce qui semble contredire l’effet classique de la longueur des mots dans le rappel sériel et libre (Baddeley et al., 1975 ; Russo et Grammatopoulou, 2003 ; Tehan et Tolan, 2007 ; Bhatarah et al., 2009). Nous fournissons une résolution possible de cette contradiction dans le cadre du modèle de récupération associative de (Romani et al., 2013).
Matériel et méthodes
Méthodes expérimentales
Les données rapportées dans ce manuscrit ont été recueillies dans le laboratoire de M. Kahana dans le cadre de l’étude Penn Electrophysiology of Encoding and Retrieval Study (voir Miller et al., 2012 pour les détails des expériences). Nous avons analysé ici les résultats des 141 participants (âgés de 17 à 30 ans) qui ont terminé la première phase de l’expérience, composée de sept sessions expérimentales. Les participants ont donné leur consentement conformément au protocole IRB de l’Université de Pennsylvanie et ont été rémunérés pour leur participation. Chaque session consistait en 16 listes de 16 mots présentés un par un sur un écran d’ordinateur et durait environ 1,5 h. Chaque liste d’étude était suivie d’un test de rappel libre immédiat. Les mots étaient tirés d’un ensemble de 1638 mots. Pour chaque liste, il y avait un délai de 1500 ms avant que le premier mot n’apparaisse à l’écran. Chaque élément était à l’écran pendant 3000 ms, suivi d’un intervalle inter-stimulus de 800-1200 ms (distribution uniforme). Après le dernier élément de la liste, il y avait un délai de 1200-1400 ms, après quoi le participant disposait de 75 secondes pour tenter de se souvenir des éléments qui venaient d’être présentés. Tous les essais ont été utilisés ; les intrusions et les répétitions ont été supprimées des essais.
Le modèle
Nous supposons que chaque mot est représenté par une population de neurones choisie au hasard dans le réseau de mémoire dédié. Nous supposons également que chaque élément récupéré agit comme un indice interne pour le suivant selon la mesure de similarité entre les éléments, qui est définie comme une la taille de l’intersection entre les populations correspondantes (le nombre de neurones qui représentent les deux éléments). En suivant (Romani et al., 2013), nous considérons le processus de récupération qui est directement déterminé par les représentations en mémoire des éléments, sans simuler explicitement l’activité du réseau. La dynamique de la récupération est décrite par une séquence d’éléments rappelés. Le premier est choisi aléatoirement parmi les éléments présentés, et chaque élément rappelé suivant est choisi pour être celui qui a une similarité maximale avec l’élément actuellement rappelé, sans compter les éléments « visités » (Romani et al., 2013). Le rappel est terminé lorsque le processus de récupération entre dans un cycle et que plus aucun élément ne peut être récupéré.
Pour mimer le protocole expérimental (voir ci-dessus), nous avons généré W = 1638 motifs binaires aléatoires de longueur N : {ξiw = 0 ; 1} avec w = 1, … , W ; i = 1, … , N indique les neurones du réseau, de telle sorte que ξiw = 1 si le neurone i participe à l’encodage de l’item mémorisé w. La similarité entre les items w et w′ est alors calculée comme Sww′=∑i=1Nξiwξiw′. Les composantes du motif pour chaque item ont été tirées indépendamment avec la probabilité pw de ξiw = 1 choisie de la manière suivante : chaque motif s’est vu attribuer arbitrairement une longueur syllabique lw = 1…4 telle que la distribution de lw à travers les motifs corresponde à la distribution correspondante à travers les mots utilisés dans l’expérience (cinq mots avec une longueur syllabique supérieure à quatre ont été combinés avec ceux de longueur quatre). Pour les motifs ayant une longueur donnée, les pw correspondants étaient distribués de façon équidistante entre 0,02 – 10-3lw et 0,02 + 10-3lw. Avec ce choix de statistiques de motifs, le nombre moyen de neurones représentant un item donné ne dépend pas de sa longueur syllabique, alors que la variance augmente avec la longueur syllabique. Les représentations des mots ont ensuite été fixées tout au long de l’expérience simulée.
Pour chaque essai de rappel simulé, L = 16 items ont été choisis pour être présentés selon deux protocoles expérimentaux. Pour le premier, les items étaient sélectionnés de manière totalement indépendante, comme dans l’expérience de Kahana. Pour le second protocole, les éléments avec le même lw ont été choisis au hasard. Le processus de rappel a été simulé comme dans (Romani et al., 2013). Le premier élément rappelé était choisi au hasard parmi les éléments présentés. Les transitions ultérieures entre les éléments rappelés étaient déterminées par la matrice de similarité S entre eux, dont chaque élément était calculé comme le nombre de neurones dans l’intersection entre les représentations correspondantes : Sww′=∑i=1Nξiwξiw′. Plus précisément, le prochain élément récupéré est celui qui a la similarité maximale avec l’élément actuellement récupéré, en excluant l’élément qui a été récupéré juste avant l’élément actuel. Le rappel est terminé lorsque le processus de récupération entre dans un cycle et que plus aucun élément ne peut être récupéré.
Résultats
Nous avons analysé un grand ensemble de données d’expériences de rappel libre effectuées par 141 sujets avec 112 essais par sujet. Les données ont été recueillies dans le laboratoire de Michael Kahana. Les listes étaient composées de 16 mots choisis au hasard dans un pool de 1638 mots. Tous les essais ont été utilisés ; les intrusions et les répétitions ont été supprimées des essais (au total 15792 essais, voir section Méthodes). Pour chaque mot, sa probabilité globale de rappel (Prec) a été calculée comme la fraction des essais où ce mot a été rappelé lorsqu’il a été présenté. La figure 1 montre la distribution de (Prec) pour tous les mots ayant un nombre donné de syllabes (en noir) agrégés à partir de tous les essais. La distribution de Prec est large pour toutes les longueurs de mots. Néanmoins, la probabilité moyenne de rappel et sa variance croissent de façon monotone avec le nombre de syllabes (le coefficient de corrélation est de 0,15, p < 10-6).
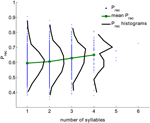
Figure 1. Probabilité de rappel pour des mots avec différents nombres de syllabes (points bleus), la distribution des probabilités de rappel (noir) et la valeur moyenne de la probabilité de rappel (vert) calculée à partir des données expérimentales. Le coefficient de corrélation entre le nombre de syllabes et la probabilité de rappel est de 0,15, p < 10-6).
Ce résultat semble contredire l’effet classique de la longueur des mots, où il a été démontré que les listes de mots courts étaient mieux rappelées que les listes de mots plus longs (Baddeley et al., 1975 ; Russo et Grammatopoulou, 2003 ; Tehan et Tolan, 2007 ; Bhatarah et al., 2009). Pour vérifier si ces deux effets peuvent être expliqués par le mécanisme de récupération que nous proposons, nous avons simulé le modèle en imitant les paradigmes expérimentaux dans deux conditions : rappel libre avec des listes composées de mots courts/longs et listes aléatoires (voir Méthodes). Un résultat surprenant est apparu : la performance dans la tâche de rappel libre dépend du paradigme expérimental – dans le rappel d’un mélange aléatoire de mots non liés, les mots plus longs sont statistiquement plus faciles à rappeler, tandis que dans les listes composées de mots avec le nombre fixe de syllabes, les mots plus courts sont plus faciles à rappeler (Figure 2).
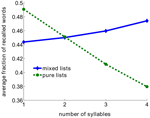
Figure 2. Fraction moyenne des mots rappelés en fonction du nombre de syllabes dans le modèle. Les listes pures sont composées en utilisant uniquement des mots ayant le même nombre de syllabes. Les listes mixtes sont composées à partir de l’ensemble des mots.
La plupart des explications des effets classiques de la longueur des mots supposent que la longueur totale des stimuli présentés est négativement corrélée avec le nombre de mots rappelés. Pour tester si cette affirmation est soutenue par les données, nous avons calculé la corrélation entre le nombre de syllabes dans les listes présentées et le nombre de mots rappelés. Nous n’avons trouvé pratiquement aucune corrélation (le coefficient de corrélation est de 0,004 et n’est pas significativement différent de 0, p = 0,67).
Discussion
L’effet de longueur des mots, c’est-à-dire l’observation que les listes de mots courts sont mieux rappelées que les listes de mots longs (Baddeley et al., 1975) est considéré comme l’un des phénomènes clés dans les théories de la mémoire à court terme (Campoy, 2011 ; Jalbert et al., 2011). Ici, nous rapportons que dans le rappel libre de mots non liés, où les mots courts et longs sont mélangés de façon aléatoire, les mots longs ont une probabilité de rappel plus élevée que les mots courts, en apparente contradiction avec l’effet de la longueur des mots.
L’effet classique de la longueur des mots est traditionnellement expliqué soit par une complexité accrue des éléments plus longs (Neath et Nairne, 1995), soit par un temps de répétition accru des éléments plus longs (Baddeley, 1986, 2003 ; Page et Norris, 1998 ; Burgess et Hitch, 1999). La première explication suggère que les mots plus courts sont généralement plus faciles à rappeler, ce qui n’est pas compatible avec notre observation. Dans la deuxième explication, un plus grand nombre de mots courts peuvent être répétés, en raison du temps de répétition plus court, et donc un plus grand nombre d’entre eux sont rappelés. Cette explication ne précise pas dans quel ordre on répéterait les mots présentés, mais elle suggère une corrélation négative entre la longueur totale des éléments présentés et le nombre de mots rappelés, alors qu’une telle corrélation n’existe pas dans les données.
Nous montrons ici que le mécanisme de récupération associative que nous avons récemment suggéré peut potentiellement rendre compte à la fois de l’effet classique de la longueur des mots (qui est également présent dans les expériences de rappel libre, voir Russo et Grammatopoulou, 2003 ; Bhatarah et al., 2009) et de l’effet inverse de la longueur dans les listes de mots choisis au hasard rapporté dans cette contribution. Contrairement aux modèles existants, la représentation neuronale à long terme des éléments joue un rôle crucial dans notre modèle, et aucun mécanisme distinct de mémoire à court terme n’est nécessaire. En particulier, la probabilité de rappel des éléments dans les listes aléatoires augmente avec la taille de sa représentation par rapport à celle des autres éléments, et ces éléments sont rappelés plus tôt et suppriment les éléments avec des représentations plus petites (Romani et al., 2013). La probabilité moyenne de rappel de l’ensemble des éléments est cependant indépendante de la taille moyenne de la représentation mais est liée négativement à la variance de la taille de la représentation dans l’ensemble de la liste (Katkov et al., soumis). Nous avons donc supposé que les mots plus longs n’ont pas, en moyenne, une représentation plus grande que les mots plus courts, mais qu’ils ont collectivement une plus grande variance de la taille de la représentation. Cette hypothèse n’a actuellement aucune justification biologique directe, mais elle nous a permis de concilier la contradiction apparente entre les observations expérimentales. En particulier, elle explique l’effet classique de la longueur des mots, où seuls les mots ayant une longueur syllabique donnée sont présentés, et donc la variance de la taille de la représentation augmente avec la longueur syllabique. Dans les listes avec une longueur syllabique mixte, dans certains essais, les éléments avec une longueur syllabique plus longue ont la plus grande représentation neuronale. Lorsque ces listes sont présentées, les mots plus longs ont une plus grande probabilité d’être rappelés, supprimant d’autres éléments d’être rappelés, résultant en une corrélation positive légère entre la longueur syllabique d’un élément et sa probabilité de rappel.
Les résultats présentés dans cette contribution montrent que la longueur du mot est un facteur proéminent qui affecte la facilité pour lui d’être rappelé. Cependant, nous notons que les probabilités de rappel montrent toujours une large distribution même pour des mots de longueur donnée, ce qui indique que d’autres caractéristiques de mots, encore inconnues, contribuent également à la probabilité de rappeler un mot.
Déclaration de conflit d’intérêts
Les auteurs déclarent que la recherche a été menée en l’absence de toute relation commerciale ou financière qui pourrait être interprétée comme un conflit d’intérêts potentiel.
Remerciements
Nous sommes reconnaissants à M. Kahana pour avoir généreusement partagé avec nous les données obtenues dans son laboratoire. Le laboratoire de Kahana est soutenu par la subvention NIH MH55687. Misha Tsodyks est soutenu par le 7e PC de l’UE (accord de subvention 604102), la Fondation scientifique israélienne et la Fondation Adelis. Sandro Romani est soutenu par une bourse à long terme du Human Frontier Science Program.
Baddeley, A. D. (1986). La mémoire de travail. Oxford, Angleterre : Oxford University Press.
Baddeley, A. D. (2003). Mémoire de travail et langage : un aperçu. J. Commun. Disord. 36, 189-208. doi : 10.1016/s0021-9924(03)00019-4
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Baddeley, A. D., Thomson, N., et Buchanan, M. (1975). La longueur des mots et la structure de la mémoire à court terme. J. Verbal Learn. Verbal Behav. 14, 575-589. doi : 10.1016/s0022-5371(75)80045-4
CrossRef Full Text | Google Scholar
Bhatarah, P., Ward, G., Smith, J., and Hayes, L. (2009). Examen de la relation entre le rappel libre et le rappel immédiat en série : modèles similaires de répétition et effets similaires de la longueur des mots, de la vitesse de présentation et de la suppression articulatoire. Mem. Cognit. 37, 689-713. doi : 10.3758/MC.37.5.689
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Burgess, N., and Hitch, G. (1999). La mémoire de l’ordre sériel : un modèle de réseau de la boucle phonologique et de sa synchronisation. Psychol. Rev. 106, 551-581. doi : 10.1037//0033-295x.106.3.551
CrossRef Full Text | Google Scholar
Campoy, G. (2011). L’interférence rétroactive en mémoire à court terme et l’effet de la longueur des mots. Acta Psychol. (Amst) 138, 135-142. doi : 10.1016/j.actpsy.2011.05.016
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Hulme, C., Suprenant, A. M., Bireta, T. J., Stuart, G., and Neath, I. (2004). Abolishing the word-length effect. J. Exp. Psychol. Learn. Mem. Cogn. 30, 98-106. doi : 10.1037/0278-7393.30.1.98
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Jalbert, A., Neath, I., Bireta, T. J., et Surprenant, A. M. (2011). Quand la longueur provoque-t-elle l’effet de longueur des mots ? J. Exp. Psychol. Learn. Mem. Cogn. 37, 338-353. doi : 10.1037/a0021804
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Miller, J. F., Kahana, M. J., et Weidemann, C. T. (2012). La terminaison du rappel dans le rappel libre. Mem. Cogn. 40, 540-550. doi : 10.3758/s13421-011-0178-9
CrossRef Full Text | Google Scholar
Neath, I., and Nairne, J. S. (1995). Effets de la longueur des mots dans la mémoire immédiate : écraser la théorie de la décroissance des traces. Psychon. Bull. Rev. 2, 429-441. doi : 10.3758/bf03210981
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Page, M. P. A., and Norris, D. (1998). Le modèle de primauté : un nouveau modèle de rappel immédiat en série. Psychol. Rev. 105, 761-781. doi : 10.1037//0033-295x.105.4.761-781
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Romani, S., Pinkoviezky, I., Rubin, A., et Tsodyks, M. (2013). Lois d’échelle de la récupération de la mémoire associative. Neural Comput. 25, 2523-2544. doi : 10.1162/NECO_a_00499
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Russo, R., et Grammatopoulou, N. (2003). La longueur des mots et la suppression articulatoire affectent les tâches de rappel à court et à long terme. Mem. Cognit. 31, 728-737. doi : 10.3758/bf03196111
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Tehan, G., and Tolan, G. A. (2007). Effets de la longueur des mots dans la mémoire à long terme. J. Mem. Lang. 56, 35-48. doi : 10.1016/j.jml.2006.08.015
CrossRef Full Text | Google Scholar